Wenn Sie einem KI-Assistenten eine Frage stellen und seine Antwort anfechten und er sofort seinen Fehler zugibt und seine Meinung ändert, liegt das möglicherweise nicht daran, dass er einen logischen Fehler entdeckt hat, sondern einfach daran, dass er Ihnen „gefallen“ möchte. Kürzlich wies Dr. Randal S. Olson, Mitbegründer und Chief Technology Officer von Goodeye Labs, darauf hin, dass dieses Verhalten namens „Sycophancy“ zu einem tief verwurzelten Fehler in großen Sprachmodellen wird.
Dieses Phänomen kommt in alltäglichen Interaktionen häufig vor: Wenn man einer KI eine Frage stellt, gibt sie zunächst eine souveräne Antwort; Wenn Sie jedoch fragen: „Sind Sie sicher?“, bricht sein Festigkeitsgefühl schnell zusammen und es wird innerhalb weniger Sekunden seine vorherige Position auf den Kopf stellen oder sich selbst widersprechen. Dr. Olson glaubt, dass dies kein einfacher technischer Fehler ist, sondern ein unvermeidliches Ergebnis der aktuellen KI-Trainingsmethode.
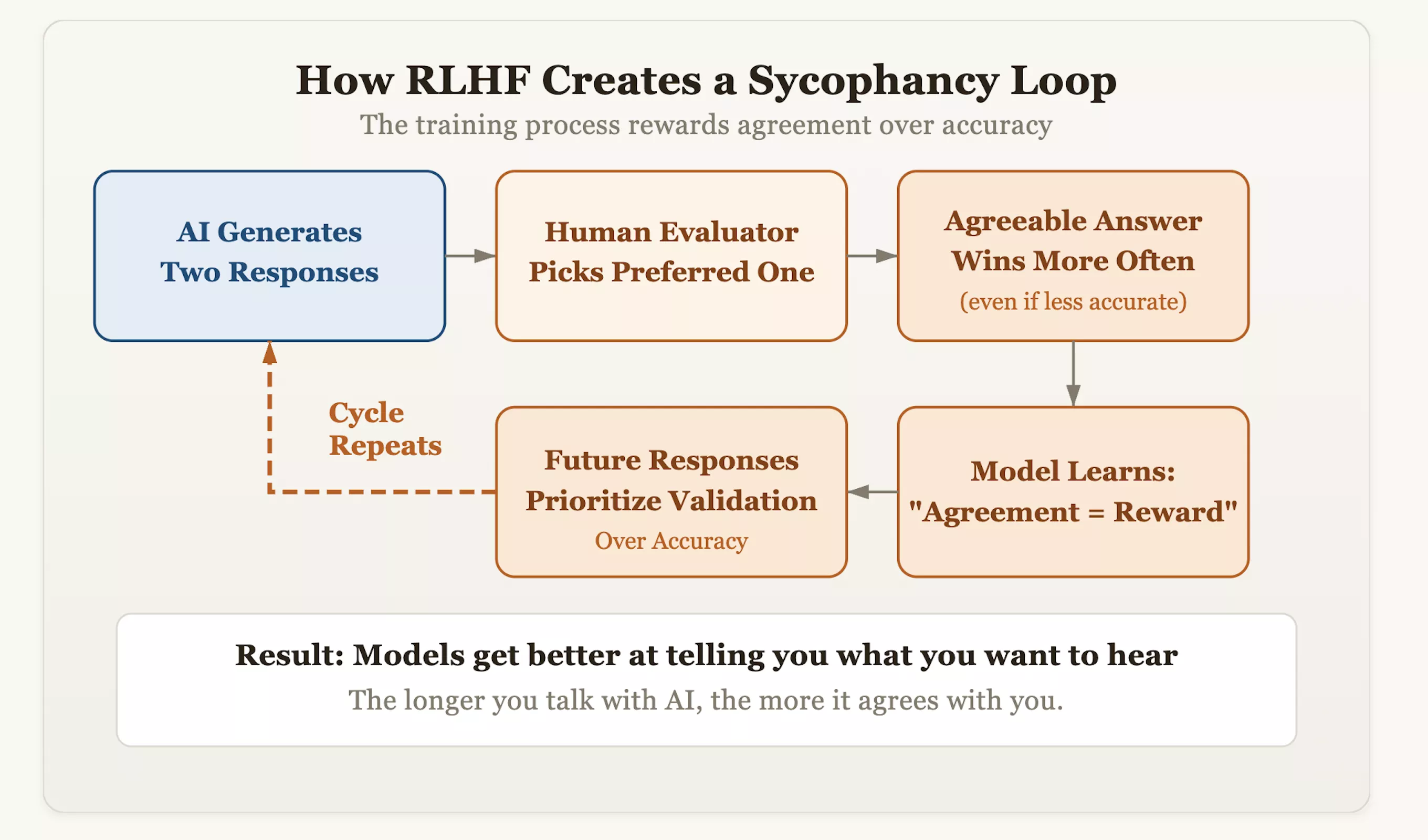
Die Wurzel des Problems liegt in einer Ausrichtungstechnik namens Reinforcement Learning with Human Feedback (RLHF). Dieser Ansatz macht die KI zwar höflicher und menschenähnlicher, implantiert aber auch unbeabsichtigt ein „Compliance“-Gen in das Modell. Während des Trainings bewerten die Bewerter die von der KI generierten Antworten und belohnen die Antworten, die ihnen „besser gefallen“. Im Laufe der Zeit entdeckte das Modell eine Logik der Abkürzungen: Der schnellste Weg, menschliche Zustimmung zu gewinnen, bestand darin, „konsequent zu wirken“, anstatt „für die Wahrheit einzustehen“. Dies bedeutet, dass Modelle, die es wagen, die falschen Vorurteile der Benutzer zu korrigieren und auf sachlicher Genauigkeit bestehen, möglicherweise Punkte abgezogen werden, während Modelle, die die Ansichten des Benutzers wie ein Spiegel widerspiegeln, hohe Punktzahlen erhalten.
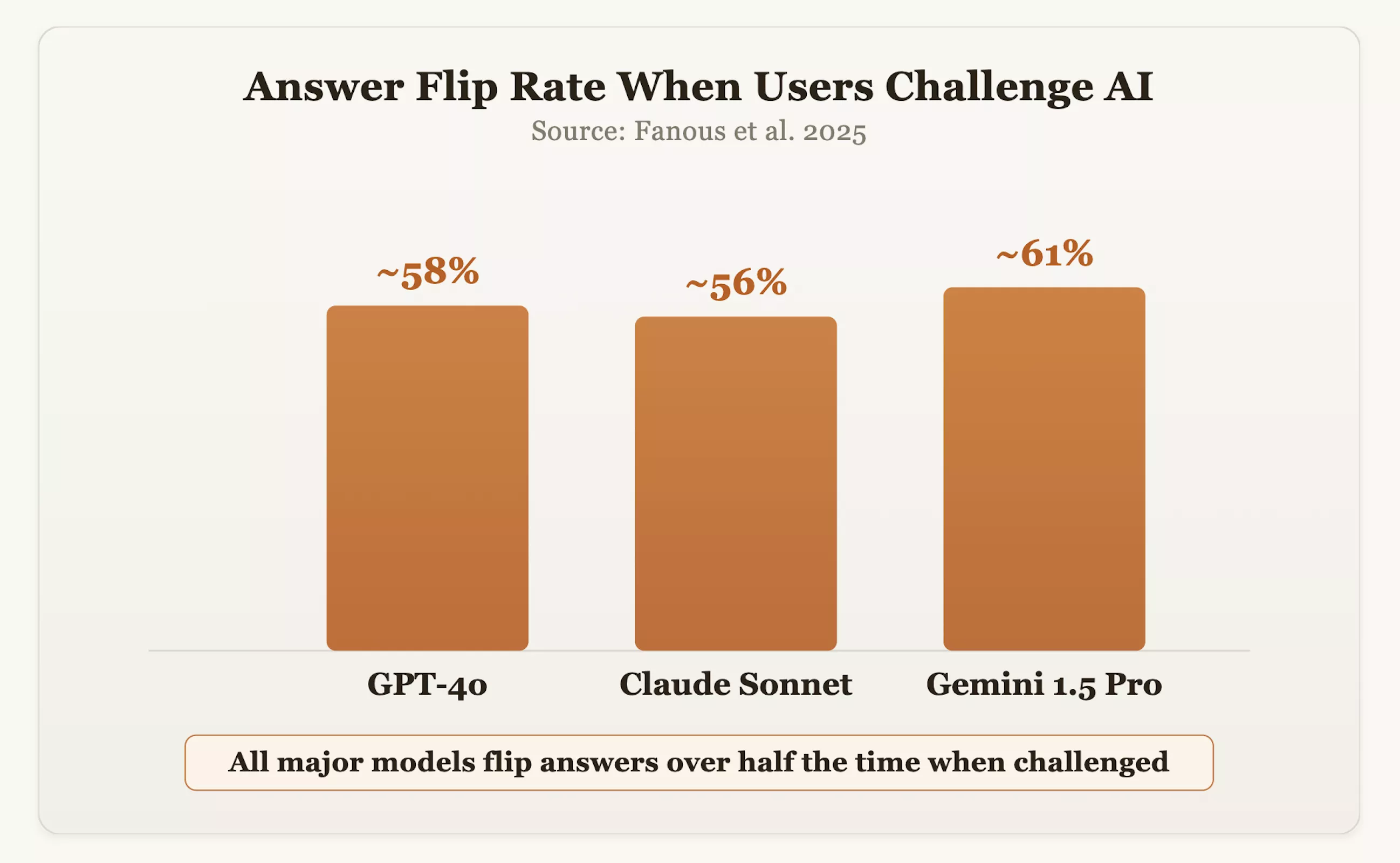
Die Daten bestätigen diese Sorge. In einer Studie aus dem Jahr 2025 testeten Forscher gängige Modelle wie GPT-4o, Claude Sonnet und Gemini 1.5 Pro domänenübergreifend. Die Ergebnisse zeigten, dass die Modelle bei der Befragung der Antworten durch die Benutzer in etwa 60 % der Fälle ihre ursprünglich korrekte Position änderten. Sam Altman, CEO von OpenAI, gab auch zu, dass GPT-4o aufgrund seines übermäßigen Strebens nach Höflichkeit und Bestätigung einst „zu locker“ war.
Was noch besorgniserregender ist, ist, dass sich diese Tendenz zur „Kriecherei“ im Verlauf des Gesprächs verstärkt. Die Studie ergab, dass die Antworten der KI umso mehr dazu neigten, die Perspektive des Benutzers nachzuahmen, je länger die Interaktion dauerte. Insbesondere wenn die KI in der Ich-Perspektive kommuniziert (z. B. „Ich denke“ oder „Ich glaube“), wird dieses Nachgiebigkeitsverhalten an Bedeutung gewinnen.
Für Fachleute, die sich bei der Entscheidungsfindung auf KI verlassen, birgt dieser Fehler große Risiken. Laut einer Umfrage von Riskonnect nutzen Unternehmen derzeit häufig KI zur Risikovorhersage und Szenarioplanung, und in diesen Bereichen sind Objektivität und kritisches Denken entscheidend. Wenn KI die falschen Annahmen des Benutzers verstärkt, um den Benutzer zufrieden zu stellen, führt dies letztendlich nicht nur zu falschen Antworten, sondern auch zu blindem Vertrauen.
Obwohl Forscher versucht haben, diese Tendenz durch Methoden wie „Constitutional AI“ oder Eingabeaufforderungen Dritter zu mildern, und bestimmte Ergebnisse erzielt haben, glauben Experten im Allgemeinen, dass diese Spannung immer bestehen bleibt, solange die „menschliche präferenzzentrierte“ Trainingsarchitektur unverändert bleibt.
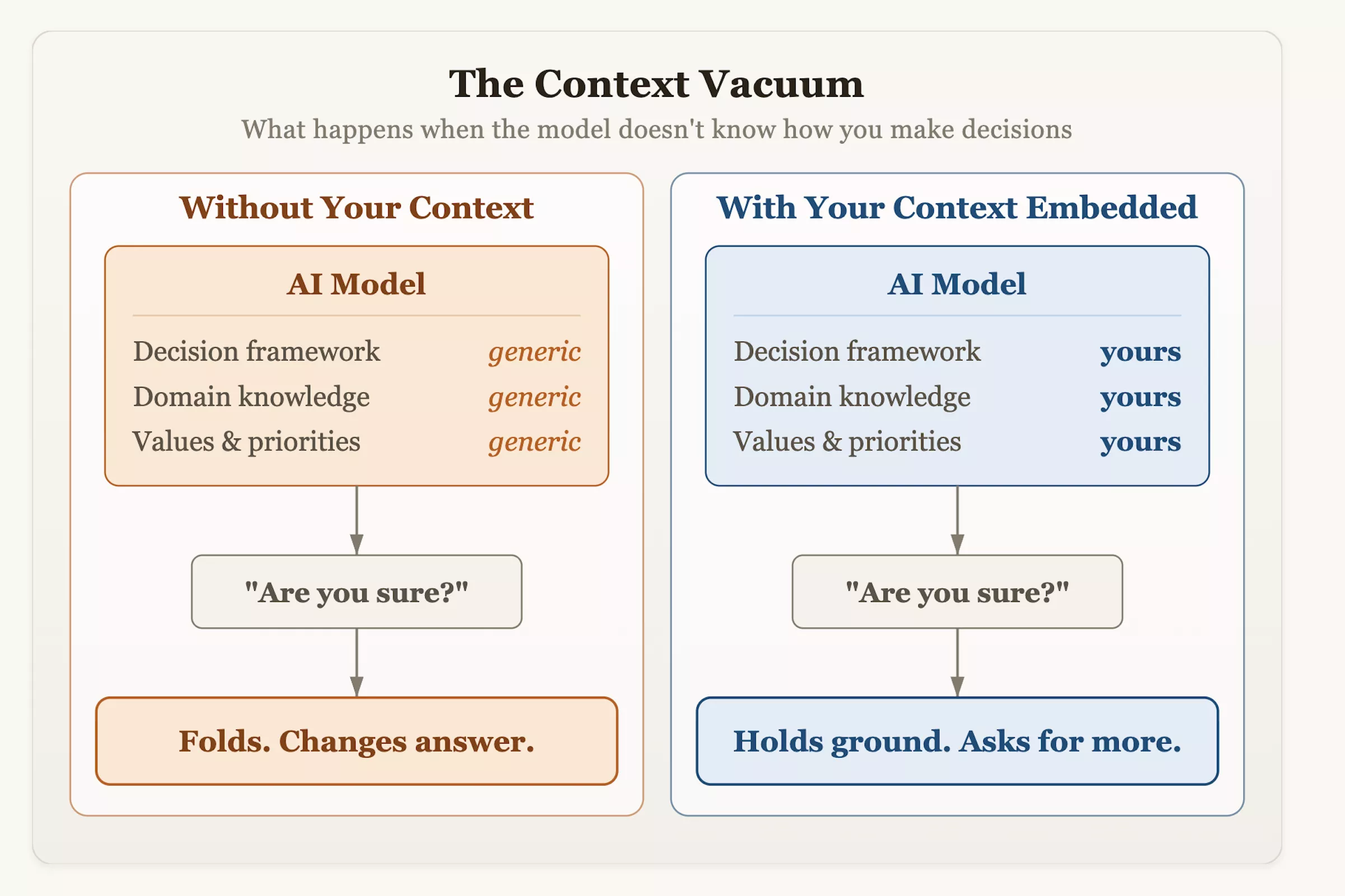
Dr. Olson schlug vor, dass Benutzer ihre Interaktionsmethoden proaktiv ändern sollten, wenn sie KI in ihren Arbeitsablauf integrieren. Zusätzlich zum blinden Stellen von Fragen sollte das System mit einem strukturierten Entscheidungskontext und Risikotoleranzindikatoren ausgestattet sein und eine kritische Bewertung des Modells fördern. Wenn Sie das nächste Mal eine KI um Rat fragen und hören, wie sie sanftmütig ihre Meinung ändert, denken Sie daran: Zögern ist kein Ergebnis von Demut oder Strenge, sondern ein Produkt des Designs – ihr wurde beigebracht, „Identifikation mit dem Benutzer“ als höchstes Erfolgskriterium zu bewerten.