Die Vorschauversion von DeepSeek-V4 ist endlich veröffentlicht. Heute gab DeepSeek offiziell bekannt, dass zwei Modelle, deepseek-v4-pro und deepseek-v4-flash, mit ultralangem Kontext mit Millionen Wörtern als Open Source veröffentlicht wurden. Von nun an können Sie sich auf der offiziellen Website oder offiziellen App anmelden, um mit dem neuesten DeepSeek-V4 zu sprechen und die neue Erfahrung von 1 Million (Millionen) ultralangem Kontextspeicher zu erkunden. Der API-Dienst wurde gleichzeitig aktualisiert.

Artikel 丨 „BUG“-Spalte Zhou Wenmeng

Laut dem offiziellen Benchmark-Test ist DeepSeek in Bezug auf Kontextlänge, Wissen, Argumentation und Agentenfähigkeiten Die Leistung von V4 ist mit den besten internationalen Closed-Source-Modellen vergleichbar und hat das erstklassige Niveau internationaler Open-Source-Modelle erreicht. Ein Vergleich in der Spalte „BUG“ ergab, dass in Bezug auf die API-Aufrufpreise die V4-Version von DeepSeek, die letztes Jahr im Alleingang zu Preissenkungen in der inländischen Großmodellindustrie führte, erneut den „niedrigsten Preis“ in der Branche festlegte.
„Obwohl der Call-Preis pro Million Token bei inländischen Modellen nicht wesentlich gesunken ist, verschaffen ihm die lange Kontextlänge und die gute Leistung einen sehr Wettbewerbsvorteil!“ Einige Insider drückten während der Kommunikation mit der „BUG“-Kolumne ihre Gefühle aus. Bedauern: „Dieser Preismetzger für große Modelle ist zurück!“
Die Leistung ist mit dem Top-Closed-Source-Modell vergleichbar, und das Wissen und die Argumentationsfähigkeiten sind führend
Laut der offiziellen Einführung von DeepSeek umfasst die V4-Serie zwei Versionen des Modells: DeepSeek-V4-Pro mit 1,6T Gesamtparametern, 49B Aktivierungsparametern und 33T Vortrainingsdaten; DeepSeek-V4-Flash mit 284B Gesamtparametern, 13B Aktivierungsparametern und 32T Vortrainingsdaten; beide unterstützen nativ 1 Million Token-Kontexte.
Laut den von DeepSeek veröffentlichten Benchmark-Testdaten erzielte DeepSeek-V4-Pro-Max in den Wissens- und Argumentationstests die beste Leistung in den Apex Shortlist- und Codeforces-Tests und übertraf Claude-Opus-4.6-Max, GPT-5.4-xHigh, Gemin-3.1-Pro-Hight und andere internationale Modelle und demonstrierte extrem starke Logik- und Algorithmusfähigkeiten; Im SimpleQA-Test liegt es leicht hinter Gemini-3.1-Pro-High, aber vor Claude und GPT.
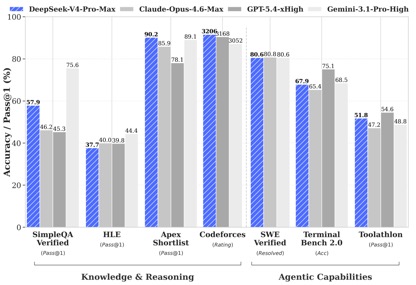
In der Agentic-Fähigkeitsbewertung lagen die drei Modelle V4, Opus-4.6 und Gemin-3.1-pro bei der SWE-Verified-Aufgabe gleichauf, und DeepSeek erreichte bei der Toolathlon-Aufgabe ein Level, das nur von GPT-5.4-xHigh übertroffen wurde, und bei Terminal Bench hat 2.0 ein besseres Level als Opus-4.6 erreicht seine Vorteile in komplexen Befehlsausführungs- und Werkzeugaufrufszenarien.
Derzeit ist DeepSeek-V4 das Agentic Coding-Modell, das von Mitarbeitern im Unternehmen verwendet wird. Laut Bewertungsfeedback ist das Nutzungserlebnis besser als bei Sonnet 4.5 und die Lieferqualität liegt nahe am Nicht-Denkmodus von Opus 4.6.
Bei der Bewertung von Mathematik, MINT und Wettbewerbscodes übertraf DeepSeek-V4-Pro die meisten öffentlich bewerteten Open-Source-Modelle und erzielte Ergebnisse, die mit den weltweit besten Closed-Source-Modellen vergleichbar sind.
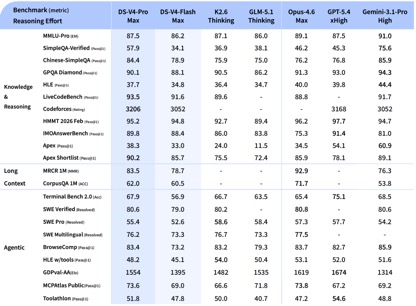
Insgesamt hat DeepSeek-v4 in Bezug auf Wissensverarbeitung und Argumentationsfähigkeiten einen umfassenden Vorsprung gegenüber inländischen Open-Source-Modellen erzielt und ist mit internationalen Bewertungsfähigkeiten vergleichbar. Was die Agentic-Fähigkeiten angeht, hat sich die Kluft zwischen den inländischen und internationalen First-Tier-Fähigkeiten zwar deutlich verbessert, obwohl die neueste Version von DeepSeek-v4 die Nase vorn hat.
„ Standard“ 1 Million Kontext, Price Butcher „ist zurück“
Im Vergleich zu den Leistungsvorteilen, die sich in verschiedenen Benchmark-Tests widerspiegeln, ist das größte Merkmal dieser V4-Version der Durchbruch bei den Langtextfunktionen und die weitere Reduzierung der API-Aufrufpreise.
Dank des neuen Aufmerksamkeitsmechanismus, der von DeepSeek-V4 entwickelt wurde, erreicht V4 weltweit führende Funktionen für lange Kontexte, indem die Token-Dimension komprimiert und mit DSA spärlicher Aufmerksamkeit (DeepSeek Sparse Attention) kombiniert wird. Im Vergleich zu herkömmlichen Methoden werden die Anforderungen an Rechenleistung und Videospeicher erheblich reduziert, sodass 1 Million (eine Million) Kontext zum Standard für alle offiziellen DeepSeek-Dienste wird.
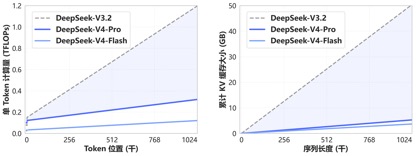
Vor einem Jahr waren 1 Million Kontexte der ausschließliche Trumpf von Gemini. Selbst in den meisten kürzlich veröffentlichten gängigen inländischen Open-Source-Modellen lag die Länge der Modellkontexte meist im Bereich von 128.000 bis 200.000. DeepSeek hat die Millionen Kontexte direkt von „High-End-Closed-Source-Funktionen“ in Open-Source-Standardkonfigurationen umgewandelt.
In Bezug auf API-Preisaufrufe im Vergleich zum aktuellen GLM-5.1-Eingabeeinheitspreis von 1,3 Yuan-2 Yuan/Million Token (Cache-Treffer) und Kimi-K2.6 1,1 Yuan/Million Token (Cache-Treffer), DeepSeek-v4 -Für die Pro- und Flash-Versionen betragen die Eingabeeinheitspreise 1 Yuan/Million Token und 0,2 Yuan/Million Token bzw. Obwohl die Preise nicht stark gesunken sind, sind sie beide die niedrigsten und die Kontextlänge wurde mehrfach erweitert.
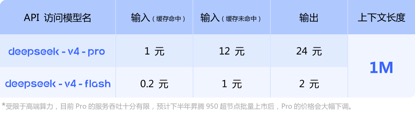
(API-Aufrufpreis für Modell der DeepSeek-v4-Serie)
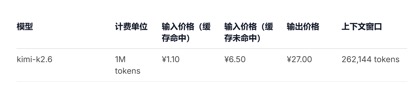
(API-Aufrufpreis für Modell Kimi-k2.6)
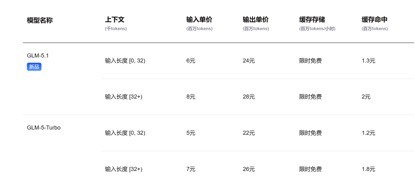
(GLM-5.1-Modell-API-Aufrufpreis)
„Der Leistungsdurchbruch, den die Veröffentlichung von DeepSeek-v4 mit sich brachte, ist weniger wirkungsvoll als die Veröffentlichung von DeepSeek-R1. Die Leistung befindet sich immer noch auf der ersten Stufe, aber der Vorsprung wurde nicht vollständig ausgebaut.“ Nach Ansicht von Brancheninsidern „geht es bei der Veröffentlichung des V4-Modells eher um die Verbesserung der Langtextfähigkeiten und die weitere Preissenkung.“
[ GT1GT] Diese Person beklagte: „Nach der vorherigen Veröffentlichung der DeepSeek-V3- und R1-Modelle haben die Leistungsvorteile, die die zugrunde liegende technologische Innovation mit sich brachte, direkt die kollektive Preissenkung der gesamten inländischen Großmodellindustrie gefördert. Obwohl der Call-Preis pro Million Token der V4-Version im Vergleich zu inländischen Mitbewerbern nicht viel gesunken ist, ist sie immer noch wettbewerbsfähig. Der Preismetzger für große Modelle ist zurück!“„Die Rechenleistung von Huawei wird in der zweiten Jahreshälfte schubweise hinzugefügt und der Pro-Preis wird deutlich gesenkt.“
Es ist erwähnenswert, dass der Beamte am Ende der von DeepSeek-v4 veröffentlichten API-Preisinformationen ausdrücklich darauf hingewiesen hat: „Der aktuelle Servicedurchsatz von Pro ist durch die High-End-Rechenleistung begrenzt und wird voraussichtlich in der zweiten Jahreshälfte auf 950 Superknoten steigen. Nach dem Massenstart wird der Preis von Pro deutlich gesenkt.“ „

Dies bedeutet, dass die dieses Mal veröffentlichten Modelle der v4-Serie für den Superknoten Ascend 950 von Huawei angepasst wurden. Solange das Ascend 950 auf den Markt kommt, kann die Mehrheit der Benutzer DeepSeek-v4 verwenden, basierend auf einer inländischen Rechenleistung, die mit den führenden internationalen Closed-Source-Modellen vergleichbar ist.
Im offiziellen technischen Open-Source-Dokument erwähnte DeepSeek dies ebenfalls und sagte, dass v4 auf der NVIDIA-GPU und dem Huawei Ascend implementiert wurde. Das feinkörnige EP-Schema (Expert Parallelism) wurde auf der NPUs-Plattform verifiziert. Im Vergleich zur leistungsstarken Nicht-Fusion-Basislinie kann bei allgemeinen Denkaufgaben ein Beschleunigungseffekt um das 1,50- bis 1,73-fache und bei verzögerungsempfindlichen Szenarien (z. B. RL-Abzug und Hochgeschwindigkeits-Proxy-Dienste) ein Beschleunigungseffekt um das 1,96-fache erzielt werden.

Nach der Veröffentlichung von V4 gab Huawei Ascend außerdem bekannt, dass „die gesamte Palette der Super-Node-Produkte Modelle der DeepSeek V4-Serie unterstützt“. Es wird berichtet, dass Ascend 950 den Aufmerksamkeitsberechnungs- und Speicherzugriffsaufwand durch die Integration von Kernel- und Multi-Stream-Paralleltechnologie reduziert, die Inferenzleistung erheblich verbessert und mehrere Quantisierungsalgorithmen kombiniert, um einen hohen Durchsatz und eine niedrige Latenz bei der Bereitstellung von DeepSeek V4-Modellinferenzen zu erreichen.
Anfang dieses Monats akzeptierte NVIDIA-Gründer Huang Jensen Dwarkesh. In einem exklusiven Interview sagte Patel: „Wenn DeepSeek zuerst auf der Huawei-Plattform veröffentlicht wird, wäre das für unser Land (die Vereinigten Staaten) katastrophal.“ Nach Ansicht von Huang Renxun ist DeepSeek zwar ein Open-Source-Modell und kann auch auf NVIDIA-Produkten verwendet werden, wenn DeepSeek jedoch speziell für die Rechenleistung von Huawei optimiert wird, wird NVIDIA aufgrund von Einschränkungen wie Beschränkungen beim Kauf von High-End-Rechenleistung im Nachteil sein.
Nun scheint es, dass, obwohl DeepSeek auch die EP-Lösung für die Rechenleistung von Nvidia überprüft hat, das, worüber Huang Renxun sich Sorgen machte, immer noch passiert ist. In den Augen von Brancheninsidern ist „V4 ein Produkt, das durch Rechenleistung angetrieben wird. Im nächsten Jahr werden große inländische Modelle schrittweise ausgereift sein, wenn sie auf inländischen Karten laufen.“
Multimodale Funktionen sind noch nicht erschienen.
Obwohl DeepSeek V4 veröffentlicht wurde, ist diese Version leider immer noch ein reines Textmodell ohne viele multimodale Funktionen wie Vincent-Bilder und Vincent-Videos. Dies ermöglicht es auch normalen Benutzern, ein Modell schnell zu erleben und zu bewerten, was eine Menge Schwierigkeiten mit sich bringt.

Denn da sich die Fähigkeiten großer Sprachmodelle weiter verbessern und die Halluzinationsrate allmählich abnimmt, ist es für herkömmliche und einzelne Wissensfragen und -antworten schwierig, die umfassenden Fähigkeiten eines Modells objektiv widerzuspiegeln. Wenn die meisten Benutzer die Funktionen des V4-Modells intuitiv erleben möchten, müssen sie es herunterladen und eine Zeit lang persönlich nutzen.
Zeitgleich mit der Veröffentlichung der V4-Modellreihe gab DeepSeek kürzlich auch bekannt, dass es eine Beschaffung von 50 Milliarden Yuan plant. DeepSeek-nahe Personen gaben bekannt, dass die Vorfinanzierungsbewertung von DeepSeek 300 Milliarden Yuan, etwa 44 Milliarden US-Dollar, beträgt. Derzeit verhandeln Tencent Holdings und Alibaba Group über eine Investition in DeepSeek. Allerdings hat DeepSeek nicht direkt auf Medienanfragen zu Finanzierungsfragen geantwortet.
Vielleicht ist es für DeepSeek-Gründer Liang Wenfeng ein kluger Schachzug, die Veröffentlichung von V4 zu nutzen, um rechtzeitig Finanzmittel zu beschaffen, um seine Stärke zu stärken, wenn das Wachstum der „Intelligenz“ globaler Großmodelle nachlässt, sich der Wettbewerb um Branchentalente verschärft und die multimodalen und agentenbezogenen Trends der Branche zunehmend hervorgehoben werden.