Am 27. Juni veröffentlichte DeepSeek den technischen Bericht von DSpark und die DeepSpec-Codebasis. Das Basismodell von DeepSeek-V4 hat sich nicht geändert. Neu ist ein serverseitiges spekulatives Decodierungsmodul: DSpark. DeepSeek bringt es auf der Modellseite von HuggingFace ganz deutlich auf den Punkt: V4-Pro-DSpark und V4-Flash-DSpark seien „keine neuen Modelle“. Diese beiden Seiten verweisen auf denselben Modellprüfpunkt sowie auf die Serviceversion, nachdem über das dekodierte Modul spekuliert wurde.

Das bedeutet, dass DSpark das Modell nicht plötzlich intelligenter macht. Ziel ist es, Antworten schneller und kostengünstiger auszuspucken, nachdem das Modell online geht.
Im technischen Bericht heißt es, dass DSpark im Onlinedienstsystem von DeepSeek-V4 eingesetzt wurde. Unter realem Benutzerverkehr wird die Generierungsgeschwindigkeit pro Benutzer von V4-Flash im Vergleich zur vorherigen MTP-1-Produktionsbasislinie, der Online-Spekulationsgenerierungslösung der vorherigen Generation von DeepSeek, um 60 % bis 85 % und von V4-Pro um 57 % bis 78 % erhöht, sofern die Durchsatzbedingungen übereinstimmen.
Auch hier muss das „Schnelle“ gemildert werden.Es bezieht sich hauptsächlich auf die Generierungsphase, also auf die Geschwindigkeit, mit der das Modell weiterhin Token ausgibt. Dies bedeutet nicht, dass die End-to-End-Antwortzeit aller Benutzeranfragen 85 % schneller ist.Das Vorabfüllen langer Eingabeaufforderungswörter, Abruf-, Tool-Aufruf-, Warteschlangen- und Netzwerkverzögerungen wirken sich immer noch darauf aus, wie lange Benutzer tatsächlich warten.
Nachdem das Modell online ist, gibt es noch ein Inferenzkonto
Diese Sache ist nicht so lebendig wie die Veröffentlichung eines neuen Modells, aber sie kommt der Realität näher, mit der KI-Unternehmen jeden Tag konfrontiert sind:Die Kosten enden nicht, nachdem das Modell trainiert wurde.
Chatbots, Code-Assistenten, Agenten und suchbasierte Produkte verbrauchen weiterhin bei jedem Anruf GPU-Zeit. Ist das Modell langsamer, müssen Nutzer länger warten; Wenn Inferenz teurer ist, wird es für Hersteller schwieriger, hochwertige Modelle für mehr Szenarien zu öffnen.
Die KI-Branche hat sich in den letzten zwei Jahren zunehmend daran gewöhnt, über Schulungskosten zu diskutieren: Wie viele GPUs muss ein Unternehmen kaufen, wie groß sollte ein Cluster aufgebaut werden und wie viel wird es kosten, das Modell der nächsten Generation zu trainieren. Aber nachdem aus dem Modell tatsächlich ein Produkt geworden ist, wird immer wieder eine andere Art von Kosten auftauchen: Schlussfolgerungen.
Schulung ist wie ein großes Projekt und Argumentation ist wie eine Stromrechnung.Solange Benutzer noch Fragen stellen, Agenten noch Aufgaben ausführen und Code-Assistenten noch Patches generieren, wird das Modell weiterhin Rechenleistung verbrauchen.
Große Modelldienste werden irgendwann auf zwei Indikatoren zurückgreifen: Geschwindigkeit und Stück-Token-Kosten. API-Preisseiten berechnen normalerweise auf der Grundlage von Eingabe-Tokens und Ausgabe-Tokens, und Unternehmen werden auch verschiedene Modelle, Caches, Routen und Kontextlängen intern in Kostenpositionen aufteilen.
DSpark kann nicht direkt mit einer Preissenkung gleichgesetzt werden, aber wenn derselbe GPU-Cluster es Benutzern ermöglichen kann, bei ähnlichem Durchsatz schneller Antworten zu erhalten, bedeutet dies, dass dieselbe Hardware mehr Benutzer bedienen kann oder das gleiche Benutzererlebnis mit weniger Karten bereitgestellt werden kann.
„Erst raten, dann testen“
Die Idee der spekulativen Dekodierung kann grob als „Erst raten, dann testen“ verstanden werden.
Wenn ein großes Modell Text generiert, spuckt es normalerweise Token für Token aus. Nachdem der vorherige Token ausgegeben wurde, weiß der nächste Token, was er abholen muss. Diese Methode ist stabil, aber langsam. Durch spekulative Dekodierung kann ein leichteres Entwurfsmodul einen Kandidaten-Token im Voraus erraten, und das große Zielmodell wird stapelweise verifiziert. Die richtige Schätzung wird direkt akzeptiert und die falsche Schätzung wird korrigiert.
Kleine Modelle können keine Entscheidungen für große Modelle treffen. Welche Token letztendlich akzeptiert werden, wird noch vom Zielmodell überprüft; Bei korrekter Implementierung ändert es die Generierungsmethode und nicht die Ausgabeverteilung des Zielmodells.Die Beschleunigung ergibt sich dadurch, dass große Modelle Kandidaten stapelweise und nicht inkrementell validieren.
Was DSpark geändert hat, ist die Art und Weise, wie ein Entwurf erstellt wird
Der Artikel begnügt sich nicht mit der Erklärung „Erst raten, dann testen“. Der Schwerpunkt liegt auf der Erstellung von Entwürfen.

Bestehende Strategieentwürfe lassen sich grob in zwei Kategorien einteilen. Der autoregressive Drafter ist stabiler, da der spätere Token den vorherigen Token sieht, aber je länger der Draft wird, desto größer wird auch die Verzögerung. Der parallele Verfasser ist schneller und kann einen ganzen Absatz auf einmal erraten, aber jede Position wird separat erraten. Die späteren Token lassen sich leicht von den vorherigen trennen, und es ist wahrscheinlicher, dass die Akzeptanzrate im Laufe der Zeit abnimmt.
DSpark geht Kompromisse ein.Das Schlüsselwort im Titel der Arbeit lautet „Semi-Autoregressive Generation“. Es verwendet zunächst eine parallele Methode, um einen Kandidaten vorzuschlagen, und verwendet dann eine leichtgewichtige sequentielle Schicht, um die bedingte Beziehung nachfolgender Token zu ändern. Dadurch bleibt nicht nur die Geschwindigkeit der parallelen Generierung erhalten, sondern auch nachfolgende Kandidaten können sehen, was zuvor erraten wurde.

Ein weiterer wichtiger Punkt ist, wie lange die Verifizierung dauert.
Je mehr Kandidaten-Token Sie erraten, desto weniger sparen Sie. Wenn Sie wissen, dass die zweite Hälfte wahrscheinlich abgelehnt wird, und sie dennoch zur Überprüfung an ein großes Modell übergeben, verbringen Sie GPU-Zeit mit einer Position mit geringem Wert.DSpark prüft die Zuverlässigkeit des Kandidaten und die aktuelle Systemlast, um die Überprüfungslänge dynamisch zu bestimmen.Wenn die GPU leer ist, können Sie mehrere Tests durchführen; Bei hoher Auslastung wird die Rechenleistung für die Teile reserviert, die mit größerer Wahrscheinlichkeit abgenommen werden.
Davon spricht das „Confidence-Scheduled“ im Titel des Papiers.

DSpark setzt auf bestehende technische Wege
DSpark steht nach Spekulationen über die bestehende Decodierungsroute und ist eher eine öffentliche Referenz, nachdem DeepSeek diese technische Route für Online-Dienste vorangetrieben hat.
SpecInfer hat bereits 2023 kleine Modellvorhersagen, Token-Baum und parallele Verifizierung in das große Modelldienstsystem integriert; Medusa schlug vor, dem Modell im Jahr 2024 mehrere Dekodierungsköpfe hinzuzufügen, um mehrere aufeinanderfolgende Token gleichzeitig vorherzusagen; Die EAGLE-Serie verbessert weiterhin die Akzeptanzrate rund um Entwurfsmodelle und dynamische Entwurfsbäume. Inferenz-Frameworks wie vLLM, SGLang und TensorRT-LLM betrachten die spekulative Dekodierung seit langem als wichtiges Werkzeug zur Reduzierung der Latenz.
Der Vorteil von DSpark besteht darin, dass es mehrere Produktionsprobleme gemeinsam behandelt: wie man Entwürfe generiert, wie man Kandidaten konsistent hält, wie sich die Überprüfungslänge mit der Last ändert und wie viel Geschwindigkeit bei echtem Online-Verkehr verbessert werden kann.
Schlüsselwörter, die in dem Papier wiederholt auftauchen, haben sich auch von „Modellfähigkeitsverbesserung“ zu dienstseitigen Begriffen wie Generierungsgeschwindigkeit pro Benutzer, angepasstem Durchsatz und Service Level Agreement (SLA) verlagert.
Dies erklärt auch, warum Sie nicht einfach die größte Zahl zum Betrachten auswählen können. Es gibt in der Arbeit tatsächlich Hochdurchsatzdaten wie 661 % und 406 %, diese basieren jedoch auf strengeren Geschwindigkeitszielen pro Benutzer: Unter dieser Einstellung liegt die alte Basislinie selbst bereits nahe an der Grenze der Servicefähigkeiten, und der relative Vorteil von DSpark wird verstärkt.
Was die normalen Vorteile wirklich veranschaulichen kann, ist der vorherige Zahlensatz: übereinstimmender Durchsatz, tatsächliche Verkehrsverteilung und das Vergleichsobjekt ist MTP-1.
Was kann DeepSpec reproduzieren?
DeepSeek ist auch Open-Source-DeepSpec. Dies ist eine Codebibliothek zum Trainieren und Bewerten spekulativer Dekodierungsentwurfsmodelle. Es umfasst Datenaufbereitungs-, Schulungs- und Bewertungsprozesse und veröffentlicht außerdem relevante Prüfpunkte für Qwen3, Gemma und andere Modelle.
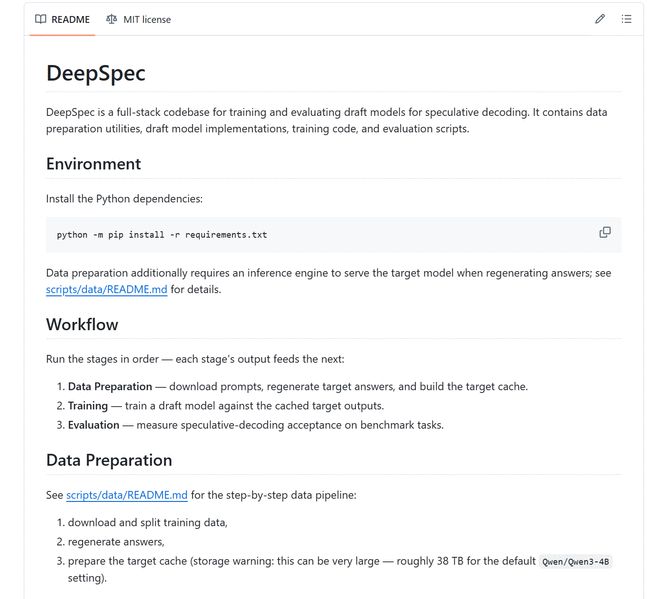
Aber,Open Source bedeutet nicht „herunterladen und reproduzieren“.Aus der Projektdokumentation geht hervor, dass der Zielmodell-Cache bei der Standardkonfiguration von Qwen3-4B möglicherweise nahe bei 38 TB liegt. Das Standard-Trainingsskript geht von 8 GPUs auf einem einzelnen Knoten aus; Sollen die Papierergebnisse angeglichen werden, müssen die Trainingseinstellungen strikt konsistent sein und in bestimmten Bereichen ist eine zusätzliche Feinabstimmung des Entwurfsmodells erforderlich.
Die Außenwelt kann einen Teil der Methode überprüfen und DeepSpec auch auf andere Open-Source-Modelle übertragen, aber die Zahlen zur Geschwindigkeitsverbesserung im DeepSeek-V4-Onlinedienst stammen immer noch aus der Hardwareskala, der Verkehrsverteilung und der Produktionssystemplanung von DeepSeek.
Open Source ist die Methode, nicht die Umgebung.
Die Community ist am meisten besorgt über wiederkehrende Grenzen
Die Diskussion über
Der KI-Forscher Ravid ShwartzZiv fasst DSpark als Kompromiss zwischen zwei Arten von Draftern zusammen: Der parallele Drafter ist schnell, aber die Akzeptanzrate nimmt entlang des Kandidatenblocks ab; Der autoregressive Drafter ist stabil, aber die Verzögerung nimmt mit der Länge des Drafts zu. Er erwähnte insbesondere zwei zu DSpark hinzugefügte Komponenten: den Confidence Judgement Head und den Load-Aware Scheduler und fügte eine wichtige Grenze hinzu: „Wie jede spekulative Dekodierung ist sie verlustfrei.“
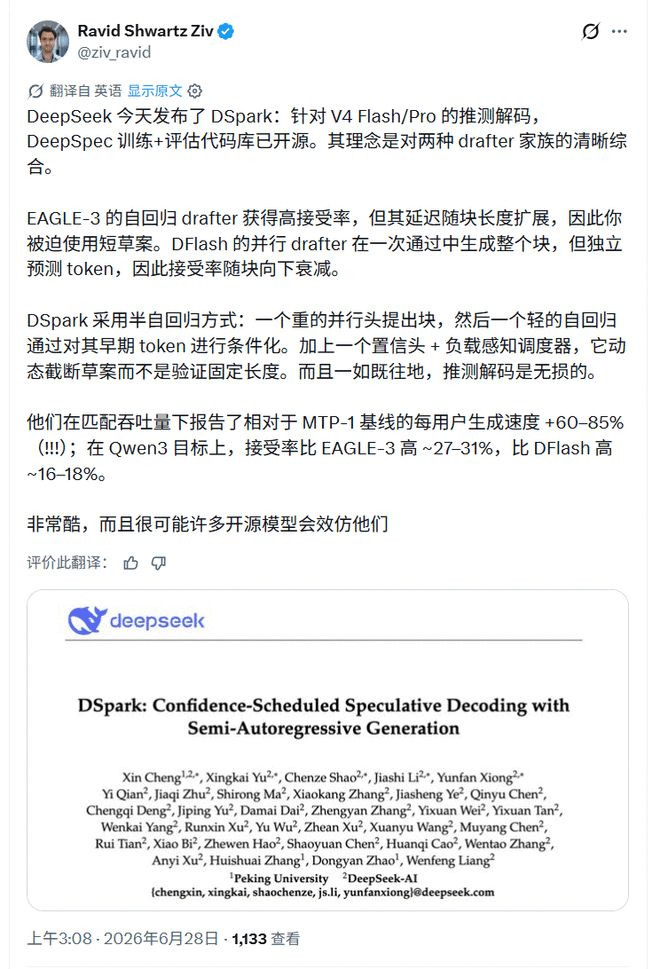
Den Ingenieuren geht es mehr darum, ob es lauffähig ist. vLLM-Mitarbeiter Rafael Caricio sagte, dass er den DSpark-Modus von DeepSeek-V4-Flash auf Dual-DGX Spark GB10 ausgeführt habe und die Single-Stream-Dekodierung etwa 60 tok/s betrug, was etwa dem 1,5-fachen von MTP-1 entspricht.
Er erwähnte auch, dass die reale Codesitzung Probleme aufdeckte, die die synthetischen Benchmarks nicht erkennen konnten: Der Engpass liegt nicht nur in der Geschwindigkeit des Rechenkerns, sondern auch in der Entwurfsakzeptanzrate, die im Langzeitkontext erheblich sinken wird.
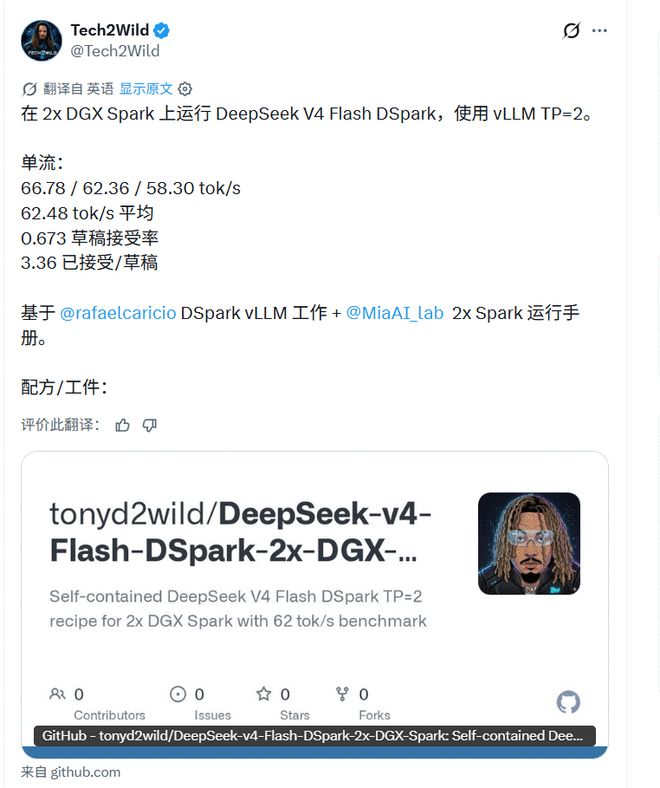
Tech2Wild lieferte auch Vor-Ort-Daten in eine ähnliche Richtung, die zeigen, dass V4-Flash-DSpark in einer bestimmten vLLM-Umgebung getestet wurde. Allerdings hängen solche Ergebnisse stark vom Hardwaremodell, der Framework-Patch-Version, der Kontextlänge und den Parallelitätseinstellungen ab. In einer anderen Umgebung können die Ergebnisse völlig anders ausfallen.
Es gibt auch Menschen, die einen gezielt an die Grenzen erinnern. AcingAI wies darauf hin
这提醒我们,DSpark的一部分优势来自负载感知调度,而调度效果天然依赖生产环境的流量规模和硬件配置。
Gleiche Leistung, weniger Rechenleistung
In einem Bericht vom 28. Juni untersuchte die South China Morning Post DSpark im Hinblick auf Inferenzengpässe, Chipdruck und Benutzerwartezeit. Diese Perspektive kommt der Produktrealität näher als „Welches Modell hat DeepSeek erneut veröffentlicht?“
KI-Unternehmen werden weiterhin Modellfähigkeiten vergleichen, aber wenn sich die Fähigkeitslücke verringert, wird auch derjenige Teil des Wettbewerbs, der die gleichen Fähigkeiten schneller und kostengünstiger bereitstellen kann.
Besonders Unternehmen wie DeepSeek müssen dies deutlich machen. DeepSeek hat niedrige Kosten und hohe Effizienz immer als wichtige Einstiegspunkte für das Verständnis der Außenwelt angesehen. Von der Beschreibung des Modelltrainings bis hin zum API-Preis ist es nicht die Frage, ob die API einen größeren Parameterumfang hat, sondern die Frage, ob sie die gleichen Funktionen billiger machen kann.
DSpark führt diese Linie fort: Es beweist nicht, dass V4 plötzlich intelligenter ist, es beweist, dass V4 bei der Bedienung von Benutzern weniger Rechenleistung verschwenden kann.
Wenn wir unsere Perspektive noch etwas erweitern, wird sich die Inferenzoptimierung auch auf die Ökologie des Open-Source-Modells auswirken. Früher galt das Open-Source-Modell als „billig“, aber wenn es tatsächlich eingesetzt wird, werden Grafikspeicher, Durchsatz, Parallelität, Latenz sowie die Komplexität von Betrieb und Wartung zu Kosten.
Wenn ein Modell Open Source sein kann, bedeutet das nur, dass es jeder bekommen kann; Ob es eine große Anzahl von Benutzern kostengünstig bedienen kann, hängt davon ab, ob der Inferenzstapel mithalten kann.
DeepSpec hat Qwen3, Gemma und andere Prüfpunkte veröffentlicht, was darauf hindeutet, dass diese Angelegenheit nicht bei DeepSeek-V4 selbst aufhört. Der Umfang der Migration hängt vom tatsächlichen Fortschritt der Community-Anpassung, der Framework-Unterstützung und der Hardware-Kompatibilität ab; aber den aktuellen öffentlichen Informationen nach zu urteilen, hat DeepSeek diesen Weg aus seinem eigenen Modell heraus übernommen.
Hier liegt der Wert von DSpark.Es fügt V4 eine Ebene von Inferenzdiensttools hinzu, die näher am Produktionssystem liegt, und nicht nur eine neue Fähigkeitsbezeichnung.
Als nächstes lohnt es sich, nicht nur zu sehen, wie schnell DeepSeek laufen kann, sondern auch, wie viele Personen diese Route passieren können. DeepSpec hat Prüfpunkte und Schulungsprozesse veröffentlicht, und es wird spekuliert, dass sich die Dekodierung von der technischen Entscheidung eines Unternehmens zu einem gängigen Mittel zur Open-Source-Inferenz wandelt, um die Kosten zu senken.Dies setzt voraus, dass andere Frameworks und Hardware mithalten können.