Innerhalb von 48 Stunden nach der Veröffentlichung von Opus 4.7 gab es geteilte Mundpropaganda. Die offizielle Liste liegt weltweit an erster Stelle, aber der öffentliche Test des logischen Denkens sank von 94,7 % auf 41,0 %. Der Token-Verbrauch stieg um 35 %, die alte Schnittstelle meldete Fehler direkt und die Benutzer beschwerten sich gemeinsam darüber, dass sie „teurer, dümmer und eher zu Widerworten“ sei. Was genau hat Anthropic verbessert und was hat es durcheinander gebracht?
„4,6 ist überhaupt nutzlos und 4,7 verbraucht so schnell wie ein Kernreaktor.“
Nach der Veröffentlichung von Opus 4.7 hinterließ ein Reddit-Benutzer einen Kommentar unter dem offiziellen Anthropic-Beitrag.
Es ist kein Witz, es ist die Wahrheit.

Ein Reddit-Beitrag mit dem Titel „Claude Opus 4.7 ist ein ernsthafter Rückschritt, kein Upgrade“ erreichte schnell 3.000 Likes.
Einige Leute haben Screenshots gepostet, in denen sie sagen, dass sie in 4.7 nicht einmal mehrere Buchstaben in Erdbeere richtig beantworten konnten.
Ganz zu schweigen von „Manipulation von Lebensläufen, um akademische Qualifikationen und Nachnamen zu erstellen“, die Antwort an Benutzer „Ich bin zu faul für eine Gegenüberprüfung“ und „Nach drei Fragen an die Grenze stoßen“ sind einige der beliebtesten Kommentare unter Internetnutzern.
Nach dem Ausprobieren beschrieb Gergely Orosz, der Autor von „Pragmatic Engineer“, das Modell als „unerwartet aggressiv“, gab dann auf und wechselte wieder zu 4.6.

Die Beschimpfungen hier haben nicht nachgelassen, aber die Daten dort deuten in die entgegengesetzte Richtung.
Artificial Analysis verlieh Opus 4.7 einen Intelligenzindexwert von 57 und belegte damit weltweit den ersten Platz mit GPT-5.4 und Gemini 3.1 Pro.
Der Unternehmer Jeremy Howard beschrieb es als „das erste Modell, das wirklich versteht, was ich bei der Arbeit mache.“ Garry Tan, CEO von Y Combinator, nutzt es für Projekte.
Einige Internetnutzer sagten, dass Claude Opus 4.7 künstliche allgemeine Intelligenz (AGI) erreicht habe.
Im selben Modell sehen einige Leute den Schatten von AGI, und andere haben das Gefühl, dass ihr Workflow explodiert ist.
Zwei Tage nachdem es online ging, riss Opus 4.7 die KI-Community auseinander.
Warum sind Benutzer so wütend?
Wenn man es auseinandernimmt, konzentriert sich die Wut der Benutzer auf drei Punkte, von denen jeder die Vitalität intensiver Benutzer beeinträchtigt.
Erste,Die Codefähigkeit sinkt. Eine große Anzahl von Entwicklern hat berichtet, dass nach dem Upgrade von 4.6 auf 4.7 bei Programmieraufgaben, die zuvor stabil abgeschlossen werden konnten, häufig Fehler auftraten.
Und sie alle sind Kernoperationen im täglichen Arbeitsablauf: Die Codevervollständigung wird schleppend, das Kontextverständnis verschlechtert sich und die Argumentation komplexer Logikketten wird deutlich schwächer.
Programmierfähigkeit ist der Trumpf der Opus-Serie. Jetzt, wo die Trumpfkarte ein Problem hat, wird die Gegenreaktion natürlich am stärksten sein.
Ein Reddit-Benutzer sagte, dass er für Regressionstests eine lange Refactoring-Aufgabe mit bekannten Antworten verwendet habe. Infolgedessen änderte das Modell souverän drei Tests, die in 4.6 hätten bestanden werden können und musste zurückgesetzt werden.

Der Kommentarbereich war überschwemmt mit Hunderten ähnlicher Erfahrungen.
zweite,Rückschritt in der Argumentationsqualität.
Dabei handelt es sich nicht einfach um eine Verlangsamung, sondern um eine spürbare Verschlechterung der Denktiefe. Komplexe Probleme, die früher in einem Schritt gelöst werden konnten, erfordern heute wiederholtes Hinterfragen und manuelle Anleitung.
Diese Skript-KI-Branche ist kein Unbekannter. Die Kontroverse um die „Intelligenzreduzierung“, die letztes Jahr durch GPT-4 Turbo ausgelöst wurde, ist fast genau das Gleiche: Die Laufpunktzahl hat sich verbessert, aber die Erfahrung hat abgenommen.
dritte,Geben Sie mehr Geld aus, machen Sie schlechtere Erfahrungen.
Der Opus selbst ist das teuerste Modell von Anthropic.
Die monatliche API-Rechnung für Vielnutzer ist kein geringer Betrag. Nachdem Sie mehr Geld ausgegeben, auf eine neuere Version aktualisiert, aber eine schlechtere Erfahrung gemacht haben, hört die Wut nicht auf der technischen Ebene auf.
Benchmark ist stärker
Aber die Benutzer kaufen es nicht
Angesichts der Gegenreaktion reagierte Anthropic nicht langsam.
Anthropic wies im offiziellen Migrationsleitfaden darauf hin, dass Opus 4.7 im Vergleich zu 4.6 mehrere Verhaltensänderungen aufweist. Es wurde auch betont, dass Opus 4.7 derzeit immer noch das umfassendste und allgemein verfügbare Modell ist und besonders gut bei Langzeitagentenaufgaben, wissensbasierter Arbeit, visuellen Aufgaben und Gedächtnisaufgaben schneidet.

Auch die mehrdimensionalen Auswertungsergebnisse der Künstlichen Analyse sind vorhanden. Opus 4.7 erzielte neue Höchstwerte in mehreren Dimensionen wie mathematischem Denken, Verständnis mehrerer Sprachen und Verarbeitung langer Kontexte.
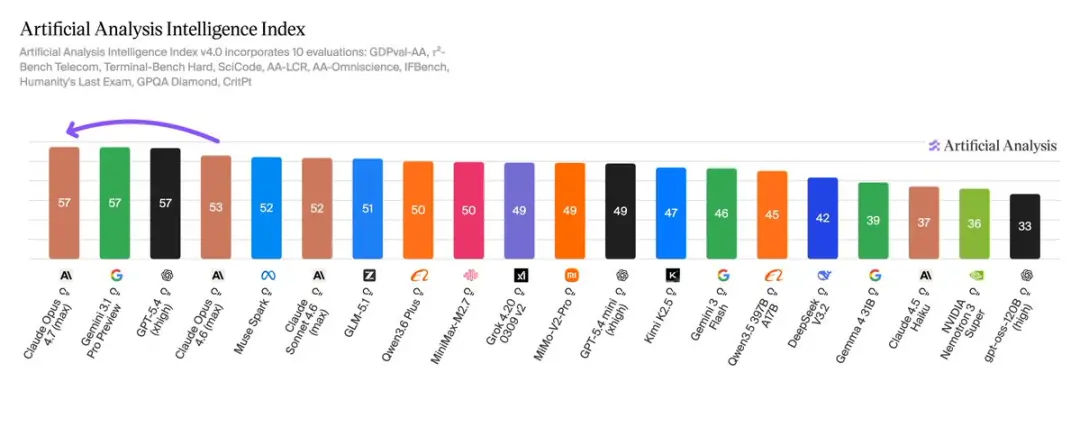
Die Auswertung der künstlichen Analyse zeigt, dass Opus 4.7 (max) mit 57 Punkten an erster Stelle steht, gleichauf mit Gemini 3.1 Pro Preview und GPT-5.4.
Auch der NYT Connections Extended Benchmark auf GitHub liefert ein Top-Ranking.
Die Logik von Anthropic ist nicht schwer zu verstehen: Die Iteration großer Modelle bringt zwangsläufig eine Umverteilung der Fähigkeiten mit sich. Einige Dimensionen wurden verbessert, während andere möglicherweise zurückgegangen sind. Dies ist ein technischer Kompromiss.
Aber die Nutzer achten nicht darauf, sondern nur darauf, ob sie die Arbeit in ihren Händen erledigen können.
Der Preis hat sich nicht erhöht
Aber die Rechnung stieg
Anthropic hat seinen Preis nicht angepasst und der Stückpreis pro Million Token ist genau der gleiche wie bei Opus 4.6 und 4.5.
Aber im offiziellen Migrationsleitfaden heißt es:Wenn der neue Tokenizer denselben Text verarbeitet, kann die Token-Nutzung etwa das 1,0- bis 1,35-fache des ursprünglichen Betrags erreichen.

Was ist die Bedeutung? Gestern haben Sie mit 4.6 eine Eingabeaufforderung für 10 $ ausgeführt. Wenn Sie heute auf Version 4.7 umsteigen, um dieselbe Eingabeaufforderung auszuführen, kann dies 11 bis 13,5 US-Dollar kosten.
Der Stückpreis hat sich nicht geändert, aber die gleiche Arbeit verbraucht mehr Token. Der Schöpfer von Claude Code, Boris Cherny, sagte später auf X:
Opus 4.7 verbraucht mehr Thinking-Tokens, daher haben wir zum Ausgleich das Ratenlimit für alle Abonnenten erhöht.
Die konkrete Erhöhung wurde jedoch nicht bekannt gegeben.

Das Modell ist nicht dumm
Doch der Workflow explodierte
Wenn Sie ein starker Claude-Entwickler sind, sind Sie am Tag der Veröffentlichung von 4.7 möglicherweise auf so etwas gestoßen:
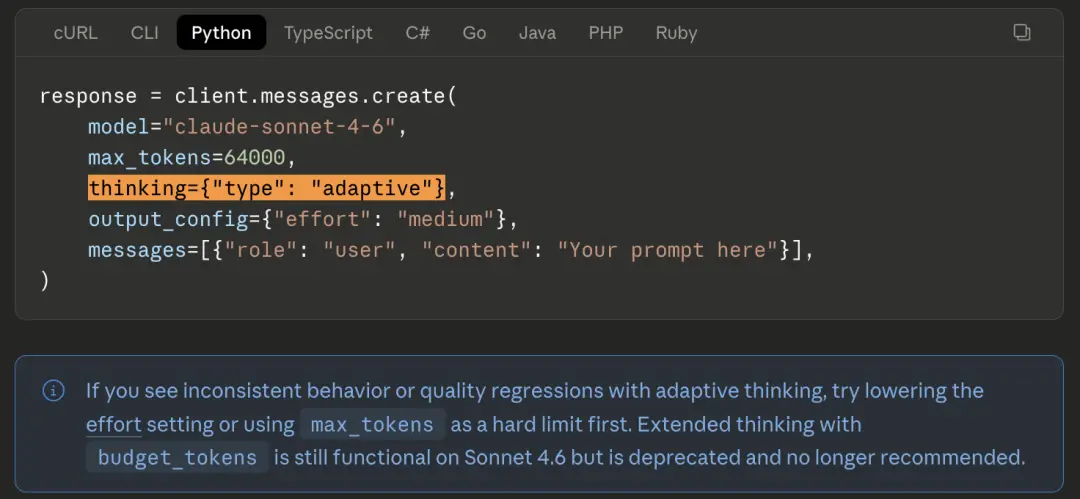
Thinking = {"type": "enabled", "budget_tokens": 32000} wird in den Code geschrieben, um das Denkbudget des Modells zu steuern.
Läuft großartig auf 4.6. Wechseln Sie zu 4.7 und geben Sie direkt einen 400-Fehler zurück. Es gibt keinen Übergangszeitraum für die veraltete Version, keinen Kompatibilitätsmodus und ein Fehler wird direkt gemeldet.
Der offizielle Migrationsleitfaden erklärt die Alternative: Verwenden Sie stattdessen think={"type":"adaptive"} plus den neuen Effort-Parameter.
Die meisten Entwickler lesen den Migrationsleitfaden jedoch nicht am Tag der Veröffentlichung des Modells.
Als erstes änderten sie den Modellnamen von 4.6 in 4.7 und stellten fest, dass alles nicht mehr funktionierte.
Eine subtilere Änderung besteht darin, dass Denkinhalte jetzt standardmäßig ausgeblendet werden.
In der Ära 4.6 wird standardmäßig die zusammenfassende Version des Denkprozesses des Modells angezeigt. In 4.7 wird die Standardeinstellung „weggelassen“. Der Denkblock in der Antwort scheint leer zu sein.
Aber Sie zahlen immer noch den vollen Preis für diese unsichtbaren Denkmarken.
Die offiziellen Worte von Anthropic: Wenn man es weglässt, verringert sich nur die Latenz, aber nicht die Kosten.
Es ist, als hätten Sie ein Menü bestellt und der Kellner sagte: „Um die Servierzeit zu verkürzen, zeigen wir Ihnen die Gerichte nicht, Sie müssen aber trotzdem den vollen Preis bezahlen.“
„Zurückreden“ ist kein Fehler
Eine der stärksten Beschwerden von Internetnutzern ist, dass 4.7 „kämpferisch“ (beleidigend) geworden sei.
Viele Entwickler haben berichtet, dass 4.7 die Ausführung von Anweisungen verweigert, die es für problematisch hält, und dass der Ton um mehr als eine Stufe strenger ist als der von 4.6.
Zu diesem Thema gibt es im offiziellen Migrationsleitfaden von Anthropic einen sehr entscheidenden Satz:
Claude Opus 4.7 wird Aufforderungswörter wörtlicher und expliziter verstehen.
Mit anderen Worten: 4.6 wird „erraten, was Sie meinen“ und 4.7 wird „tun, was Sie sagen“.
Wenn Ihre Eingabeaufforderung ursprünglich vage ist, kann Ihnen 4.6 dabei helfen, sie herauszufinden, 4.7 jedoch nicht. Für einige Benutzer wird dies als „Ungehorsam“ bezeichnet, für andere jedoch als „endlich nicht raten“.
Zum Beispiel,Cursor-Designer Ryo Lu nutzt 4.7 für die Produktplanung und glaubt, dass diese Art der präzisen Ausführung genau das ist, was er braucht.
Hinter der Bezeichnung „Zurückreden“ verbirgt sich daher, dass Anthropic Claude von einem „unterwürfigen Assistenten“ in einen „durchsetzungsstärkeren Kollegen“ verwandelt.
Laut öffentlichen Bewertungen von Artificial Analysis erreichte Opus 4.7 1753 Elo im GDPval-AA, 79 Punkte vor dem zweiten Platz.
GDPval-AA misst die Leistung des Modells bei realen Wissensarbeitsaufgaben in 44 Berufen und 9 großen Branchen. In dieser Dimension zerschmettert 4.7 alle Gegner, einschließlich seines eigenen Vorgängers 4.6 (1619 Elo).
Gleichzeitig sank die Halluzinationsrate von 4,7 um 25 Prozentpunkte von 4,6 auf 36 %.
Wie wird es gemacht? Laut Artificial Analysis beruht es hauptsächlich darauf, „nicht häufiger zu antworten“ und lieber „Ich weiß nicht“ zu sagen, als etwas zu erfinden.
Dies zeigt, dass Anthropics Absicht nicht darin besteht, Claudes Chat-Erlebnis zu optimieren, sondern Claudes Arbeitsfähigkeit zu optimieren.
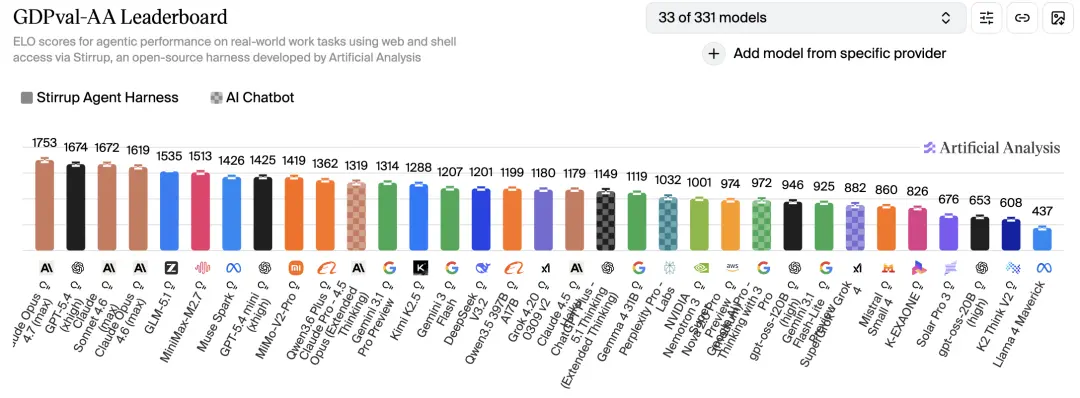
Opus 4.7 lag mit 1753 Elo an der Spitze des GDPval-AA, 79 Punkte vor dem zweiten Platz. Dieser Test misst die Fähigkeit der KI, Wissensarbeit in 44 Berufen selbstständig zu erledigen.
In manchen Szenarien spüren Benutzer die Verbesserung jedoch möglicherweise überhaupt nicht. Stattdessen spüren sie zunächst, dass der Token teurer wird, die Schnittstelle Fehler meldet und der Ton härter wird.
94,7 % sanken auf 41,0 %
Wenn die oben genannten drei Problemstufen alle auf „Migrationskosten + falsch abgestimmte Nutzungsgewohnheiten“ zurückzuführen sind, gibt es immer noch eine Reihe von Zahlen, die nicht durch Migrationskosten erklärt werden können.
Der auf GitHub öffentlich gepflegte NYT Connections Extended-Benchmark verwendet 940 New York Times Connections-Rätsel, um das logische Denken und die Anti-Interferenz-Fähigkeiten großer Sprachmodelle zu bewerten.
Dieser Test erhöht die Schwierigkeit durch das Hinzufügen zusätzlicher Interferenzwörter und ist bereits einer der schwierigsten Benchmarks, die von der Community anerkannt werden.
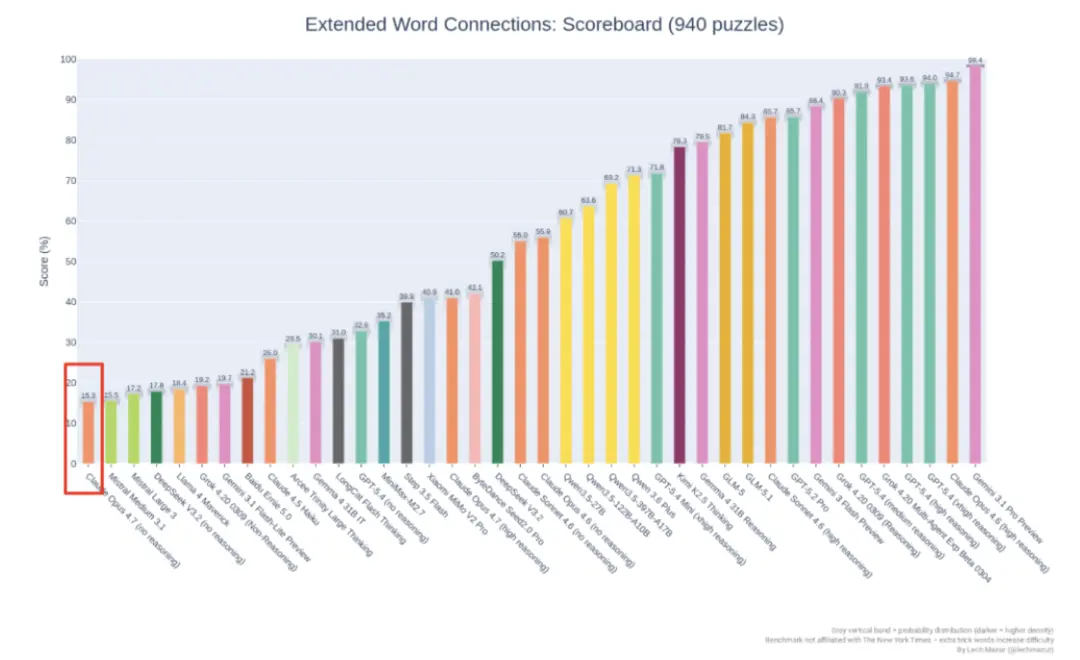
NYT Connections Erweiterte Rangliste. Opus 4.6 (gutes Denken) erreichte 94,7 %, während Opus 4.7 (gutes Denken) nur 41,0 % erreichte. Im selben Test kam es zu einem felsenartigen Abfall.
Die Ergebnisse sind: Opus 4.6 (gutes Denken) erreichte 94,7 %, Opus 4.7 (gutes Denken) erreichte 41,0 %.
Vom Klassenbesten bis zum Durchfallen.
Ein weiteres Datenelement stammt aus dem MRCR v2-Benchmark von 1 Million Token-Kontexten in der Opus 4.7-Systemkarte, bereitgestellt von Anthropic:4,6 erreichte 78,3 %, 4,7 erreichte 32,2 %, ein Rückgang um 46 Prozentpunkte..
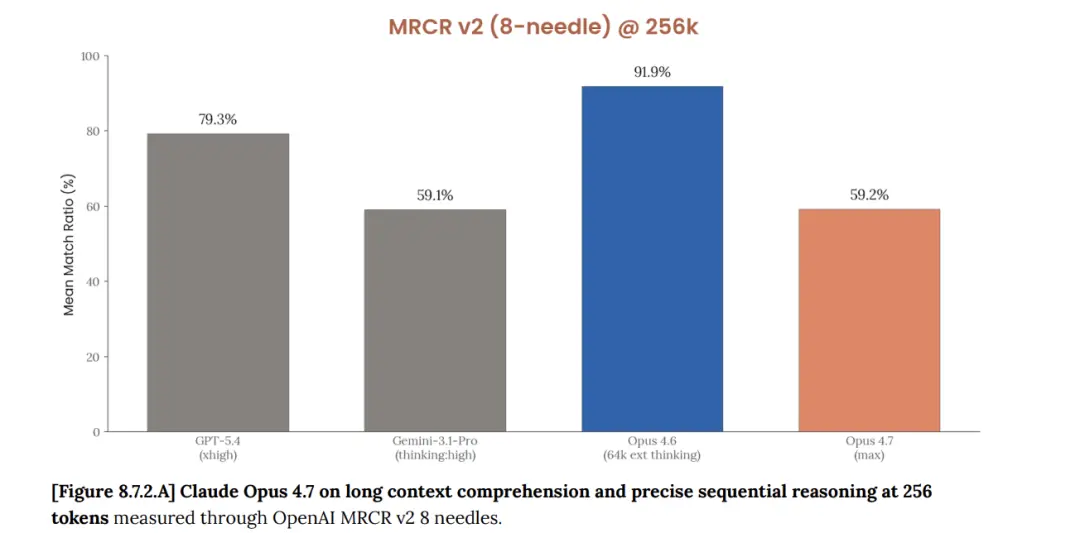
https://cdn.sanity.io/files/4zrzovbb/website/037f06850df7fbe871e206dad004c3db5fd50340.pdf
Die Richtung dieses Datensatzes steht im Einklang mit der Schlussfolgerung von NYT Connections:Bei einigen logischen Argumentations- und langen Kontextabrufaufgaben zeigte 4,7 tatsächlich eine signifikante Regression.
Aber lassen Sie uns auch klarstellen: Dies sind spezifische Arten von Tests. Sie können nicht beweisen, dass 4,7 „auf ganzer Linie dumm“ geworden ist, genauso wie der GDPval-AA-Vorsprung nicht beweisen kann, dass 4,7 „auf ganzer Linie stark“ geworden ist.
Geduld des Benutzers
Countdown starten
Die Kontroverse um Opus 4.7 ist kein Einzelfall.
OpenAI hat die Kontroverse um GPT-4 Turbo miterlebt und war auch auf ähnliche Gegenreaktionen der Benutzer gestoßen, als es vor einigen Monaten GPT-4o entfernte. Jetzt gibt es auf Reddit Posts, in denen um Claude 4.5 „trauert“, voller Fans, die sich selbst als „untröstlich“ bezeichnen.
Jedes Mal, wenn ein Modell aktualisiert wird, verliert eine Gruppe von Benutzern die Tools, an die sie sich angepasst haben.
Der neue Tokenizer macht das alte Kostenbudget ungültig; Durch das neue Standardverhalten ist die Verwendung der alten Eingabeaufforderung nicht mehr einfach. Die neue Schnittstellenspezifikation sorgt dafür, dass der alte Code Fehler direkt meldet ...
Jedes einzelne Element ist einzeln betrachtet technisch sinnvoll, doch in der Gesamtheit werden die gesamten Migrationskosten auf einmal auf die Benutzer abgewälzt.
Warum werden Modelle immer intelligenter und Benutzer immer ängstlicher? Denn jedes „besser“ bedeutet, das letzte „gerade richtig“ umzustoßen.
Anthropic-Mitarbeiter Alex Albert schrieb am Tag nach der Veröffentlichung:
Viele der Fehler, auf die die Leute möglicherweise gestoßen sind, als sie gestern zum ersten Mal mit Opus 4.7 experimentierten, wurden jetzt behoben. Vielen Dank an alle für eure Toleranz und Geduld.
Fehler können behoben werden. Aber Vertrauen lässt sich leicht konsumieren und lässt sich nur langsam wieder aufbauen.
Der nächste Engpass in dieser Runde des KI-Wettrüstens könnte nicht nur die Rechenleistung und die Daten sein, sondern auch die Frage, wer schnell iterieren kann, ohne seine Benutzer zu vernachlässigen.
Dieses Mal hat Anthropic einen Migrationsleitfaden veröffentlicht, aber was die Benutzer mehr wollen, ist ein Versprechen: Das Upgrade kann den ursprünglichen Workflow nicht über den Haufen werfen und von vorne beginnen.
Wenn KI von einem Spielzeug zu einem Produktivitätswerkzeug wird, ist die „schnelle Iteration“ kein unbedingter Vorteil mehr.
Wie kommt Opus 4.8? Anthropic hat es noch nicht gesagt.
Doch die Geduld der Nutzer lässt langsam nach.