Intel hat auf dem VLSI-Symposium in Hawaii offiziell den neuen Intel 18A-P Foundry-Prozessknoten angekündigt, der eine wichtige Verbesserung und Optimierung auf Basis des bestehenden Intel 18A darstellt. Offizielle Daten zeigen, dass 18A-P bei gleichem Stromverbrauch eine Leistungsverbesserung von 9 % bewirken kann; und bei gleichem Leistungsniveau kann der Stromverbrauch um etwa 18 % gesenkt werden. Gleichzeitig wird die Wärmeleitfähigkeit auf Chipebene um 20–40 % verbessert und der Durchgangswiderstand (Via) auf wichtigen Ebenen wird ebenfalls um etwa 10–30 % verringert.
Intel sagte, der Prozess sei in die Risikopilotproduktion eingetreten und werde der erste sein, der in seinem Xeon-Serverprozessor der nächsten Generation „Diamond Rapids“ zum Einsatz komme.

Um die oben genannten Indikatoren zu erreichen, hat Intel den 18A-Prozess hinsichtlich der physischen Struktur und der Designbibliothek angepasst und erweitert. Was die Standard-Einheitenbibliotheken betrifft, hat das Unternehmen den 180HP- und 160HD-Bibliotheken eine Vielzahl von Einheitenoptionen hinzugefügt, um breitere Stromverbrauchs- und Leistungsbereiche der Produkte abzudecken: Für Designs mit geringem Stromverbrauch wurden neue W1- und W1.5-Einheiten hinzugefügt; Für Hochleistungsszenarien hat das Unternehmen die W3P-Einheit mit einem „Dual-Contact“-Design auf den Markt gebracht, das die Leistung im Vergleich zur bestehenden W3-Einheit weiter verbessert, ohne die Grundfläche zu vergrößern.

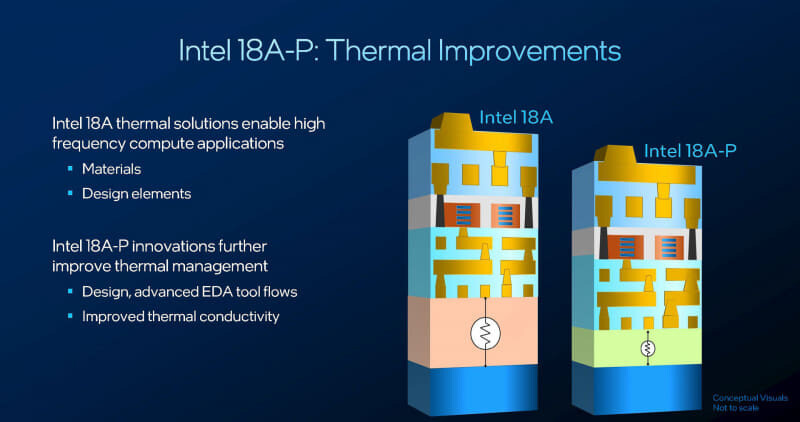
Auf der Ebene des Wärmemanagements hat Intel ein neues wärmeleitendes Material auf der Vorderseite des Wafers integriert, um den Wärmewiderstand auf der Vorderseite des Chips deutlich zu reduzieren und so die Wärmeleitungseffizienz von der Transistorschicht zum Verpackungs- und Wärmeableitungssystem zu verbessern. Gleichzeitig hat Intel auch seine EDA-Designtools aktualisiert und Layout- und Layoutfunktionen eingeführt, die empfindlicher auf die Temperaturverteilung reagieren. Dadurch kann das Designteam während der physischen Designphase eine detailliertere Optimierung von Wärmepunkten und Wärmeableitungspfaden durchführen und so die Stabilität und nachhaltige Leistungsabgabe des Produkts in Hochlastszenarien strukturell verbessern.
Das erste Produkt, das den 18A-P-Prozess von Intel nutzt, wird der Xeon 7-Level-Serverprozessor „Diamond Rapids“ der nächsten Generation sein, dessen Kernrechenkacheln vollständig auf der Basis dieses neuen Knotens aufgebaut werden. Die Gesamtarchitektur von „Diamond Rapids“ setzt die immer beliebter werdende „Small-Chip“-Idee aktueller High-End-Server-CPUs fort, die AMD EPYC ähnelt: Eine große Anzahl von CPU-Kernen wird mithilfe fortschrittlicher Technologie in mehrere Rechenchiplets aufgeteilt und dann über zentralisierte I/O-Ressourcen miteinander verbunden, um eine ausgewogenere und nahezu konsistente Speicherzugriffsverzögerung zu erreichen und die Erweiterung auf höhere Kernzahlen und Bandbreitenkonfigurationen innerhalb desselben Pakets zu erleichtern.

Im Paket ist „Diamond Rapids“ mit vier Rechenkacheln (Compute Tiles) konfiguriert, die Intel auch „Core Building Blocks“ (CBB) nennt. Jeder Rechenchip basiert auf dem 18A-P-Prozess, integriert 48 Performance-Kerne (P-Core) mit dem Codenamen „Panther Cove“ und ist mit einem lokalisierten Level-3-Cache (L3-Cache) ausgestattet. Nachdem die vier Rechenchips gestapelt wurden, erreicht die Gesamtzahl der CPU-Kerne im gesamten Prozessorpaket 192. Im Gegensatz zu vielen früheren Xeon-Designs ermöglicht diese Generation von Kernen keine Hyper-Threading-Technologie, sodass die gesamte Plattform eine 192-Kerne/192-Thread-Konfiguration ist, die sich auf Single-Thread-Leistung und Kernstapelung konzentriert, um den Anforderungen von Server- und Cloud-Computing-Lasten mit hoher Dichte gerecht zu werden.

Was die I/O- und Speichersubsysteme betrifft, übernimmt „Diamond Rapids“ ein vom Rechenchip getrenntes Design: Vier Rechenchips sind über Verbindungen mit zwei I/O- und Memory-Hub-Chiplets (IMH, I/O und Memory Hub) verbunden. Es wird erwartet, dass die beiden IMH-Chiplets relativ ausgereifte Prozessknoten wie Intel 3 nutzen, um ein Gleichgewicht zwischen Kosten und Energieeffizienz zu schaffen. Jedes IMH-Chiplet integriert einen 8-Kanal-DDR5-Speichercontroller, sodass das gesamte Prozessorpaket insgesamt 16-Kanal-DDR5-Speicher unterstützt und so Speicherszenarien mit hoher Bandbreite und hoher Kapazität unterstützt.
Was den Erweiterungsbus betrifft, wird „Diamond Rapids“ Intels erste Serverprozessorplattform sein, die PCI Express 6.0 offiziell einführt. Im Vergleich zum derzeit weit verbreiteten PCIe 5.0 verdoppelt PCIe 6.0 die bidirektionale Bandbreite und bietet umfangreichere Verbindungsmöglichkeiten für leistungsstarke Beschleunigerkarten, Speichergeräte und Hochgeschwindigkeits-Netzwerkschnittstellen. Allerdings hat Intel die konkrete Anzahl der PCIe-Lanes und den Zuteilungsplan für die Plattform nicht bekannt gegeben und es wird erwartet, dass diese in späteren Produktveröffentlichungen oder Plattform-Briefings näher bekannt gegeben werden.

Aufgrund der Integration mehrerer großer Rechen- und I/O-Chiplets, die über komplexe Verbindungs- und Stromversorgungsnetzwerke in das Gehäuse integriert sind, verwendet „Diamond Rapids“ ein größeres Gehäusesubstrat und führt einen neuen LGA9324-Prozessorsockel ein. LGA9324 verfügt über eine extrem hohe Anzahl an Kontakten, um den Bedarf des Prozessors an Stromversorgung, Speicherkanälen, PCIe-Kanälen und anderen Hochgeschwindigkeitsschnittstellen zu decken. Dies weist auch darauf hin, dass diese Plattform hauptsächlich auf High-End-Rechenzentren und Unternehmensservermärkte ausgerichtet ist.
Nach dem aktuellen Zeitplan von Intel soll die Xeon 7 „Diamond Rapids“-Familie voraussichtlich im Jahr 2027 offiziell auf den Markt kommen und mit modernster Prozesstechnologie und kleiner Chip-Architektur mit anderen Serverprozessoren der Branche konkurrieren. Für Intel sind der 18A-P-Prozess und die von „Diamond Rapids“ repräsentierten Produkte nicht nur ein wichtiger Teil seiner Prozess-Roadmap, sondern gelten auch als wichtiges Verhandlungsinstrument für die Neugruppierung im Rechenzentrums- und Serverbereich und die direkte Auseinandersetzung mit Gegnern.