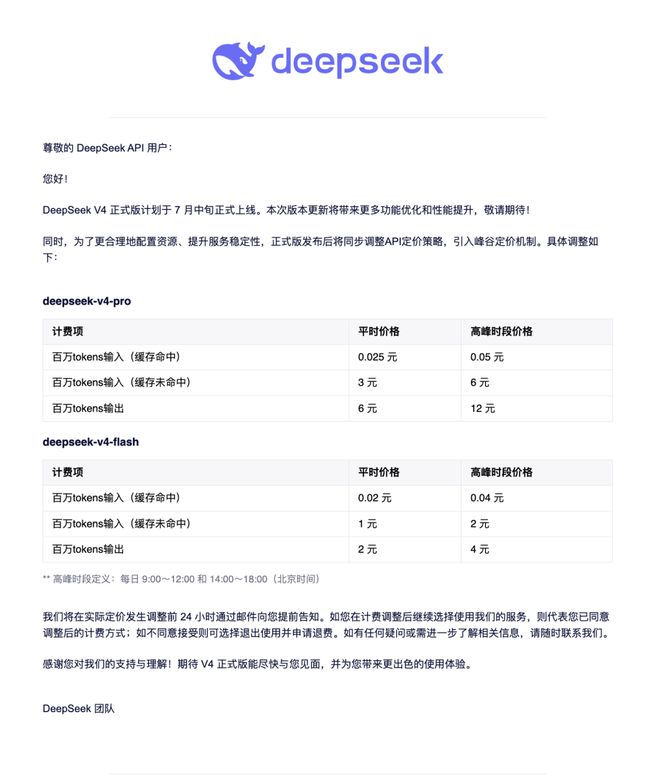
Am 29. Juni zeigte eine von DeepSeek an Benutzer gesendete Upgrade-Erinnerungs-E-Mail, dass die offizielle Version von DeepSeek V4 Mitte Juli offiziell veröffentlicht werden soll und weitere Funktionsoptimierungen und Leistungsverbesserungen sowie einen Peak-and-Valley-Preismechanismus mit sich bringen wird. Laut E-Mail gelten täglich 9:00 bis 12:00 Uhr und 14:00 bis 18:00 Uhr Pekinger Zeit als Hauptverkehrszeiten, und der Anrufpreis ist doppelt so hoch wie der übliche Preis. Gleichzeitig erklärte DeepSeek, dass es die Benutzer 24 Stunden im Voraus per E-Mail benachrichtigen werde, bevor relevante Anpassungen vorgenommen würden.
„Dauerhafte Preissenkung“ vor „Preiserhöhung“
Berichten zufolge ist dies nicht das erste Mal, dass DeepSeek in diesem Jahr die Preise anpasst. Aus dem offiziellen API-Dokument geht hervor, dass DeepSeek pro Million Token abgerechnet und separat basierend auf Cache-Hits, Cache-Misses und Ausgabe-Tokens berechnet wird. Gleichzeitig stellt die DeepSeek V4-Serie selbst hohe Anforderungen an die Rechenleistung.
Als DeepSeek am 24. April V4 Preview veröffentlichte, gab es an, dass V4 Pro über 1,6 Billionen Gesamtparameter und 49 Milliarden Aktivierungsparameter verfügt und V4 Flash über 284 Milliarden Gesamtparameter und 13 Milliarden Aktivierungsparameter verfügt. Beide unterstützen den Kontext von 1 Million Token.
Das offizielle Dokument zeigt auch, dass das Parallelitätslimit von V4 Flash 2500 beträgt; Während das Hochleistungsmodell von V4 Pro ein Parallelitätslimit von 500 hat und seine Angebotselastizität schwächer ist als die von Flash.
Am 23. Mai kündigte DeepSeek an, den bisherigen Rabatt von 75 % auf V4 Pro in einen dauerhaften Preis umzuwandeln und die API-Gebühr von bisher maximal 24 Yuan/Million Token auf maximal 6 Yuan/Million Token zu senken. Der Markt spekulierte damals, dass es möglicherweise mit dem erhöhten Angebot an Huaweis Ascend 950-Chips zusammenhängt, DeepSeek reagierte jedoch nicht darauf.
Nach der dauerhaften Preissenkung beträgt der aktuelle Normalpreis von V4 Pro 0,025 Yuan/Million Token für die Cache-Hit-Eingabe, 3 Yuan/Million Token für den Cache-Miss und 6 Yuan/Million Token für die Ausgabe. Die entsprechenden Preise für V4 Flash betragen 0,02 Yuan, 1 Yuan bzw. 2 Yuan. Während der Hauptverkehrszeiten verdoppeln sich diese Preise, sind aber immer noch niedriger als bei der vorherigen Veröffentlichung.
Für normale Benutzer spiegelt sich diese Anpassung möglicherweise nicht direkt in den Änderungen der Chat-Anwendungsgebühren wider; Betroffen sind vor allem Entwickler, KI-Anwendungsunternehmen und Unternehmenskunden, die über APIs auf das DeepSeek-Modell zugreifen.
Am Beispiel von V4 Pro betragen die normalen Kosten bei der Berechnung der Ausgabe-Tokens etwa 600 Yuan und der Spitzenpreis etwa 1.200 Yuan, wenn eine KI-Anwendung in Spitzenzeiten 100 Millionen Ausgabe-Tokens pro Tag verbraucht. Wenn es 1 Milliarde Output-Token pro Tag verbraucht, steigen die Kosten von etwa 6.000 Yuan auf 12.000 Yuan. Bei hochfrequentierten Anwendungen wie Kundenservice, Code-Assistenten, Büroagenten und suchgestützten Fragen und Antworten kann sich eine Verdoppelung des Preises direkt auf die Bruttogewinnmargen und Anrufstrategien auswirken.
Es geht nicht darum, auf den Niedrigpreisweg zu verzichten
Derzeit bedeutet die Einführung von Peak- und Valley-Preisen durch DeepSeek nicht, den Niedrigpreisweg aufzugeben. Genauer gesagt hat DeepSeek die Rechenressourcen einfach nach Nutzungsdauer neu geschichtet, sodass sich seine Niedrigpreisstrategie von einheitlicher Billigkeit zu raffinierter Billigkeit zu ändern begann.
Denn nur gemessen an der Preisgestaltung der Token liegt DeepSeek nach der Einführung der Spitzen- und Talzeit immer noch im Niedrigpreisbereich „wirklich duftend“ und ist auf dem internationalen Markt immer noch sehr wettbewerbsfähig. Dies ist auch der Grund für die Preiserhöhung von DeepSeek.
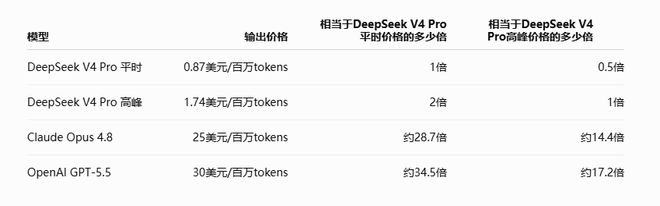
Laut der DeepSeek English API-Preisseite beträgt der Ausgabepreis von V4 Pro 0,87 US-Dollar/Million Token, was etwa 1,74 US-Dollar basierend auf der Spitzenverdopplung entspricht. Im Gegensatz dazu zeigt die offizielle Preisseite von OpenAI, dass der Standard-API-Preis von GPT-5.5 5 US-Dollar für die Eingabe, 0,5 US-Dollar für die Cache-Eingabe und 30 US-Dollar für die Ausgabe/Million Token beträgt; Der reguläre Preis für Claude Opus 4.8 von Anthropic beträgt 5 US-Dollar für Input und 25 US-Dollar für Output/Million Token.
Wenn wir nur die Ausgabe-Token betrachten, liegt der Preis der High-End-Modelle von OpenAI und Anthropic immer noch etwa 14-17-mal über dem Spitzenpreis von DeepSeek V4 Pro.
Da sich andererseits das Preismodell großer Modelle in Überseemärkten von festen Abonnements auf die Abrechnung über Token verlagert, beginnen die Nutzungskosten von Unternehmen dramatisch zu steigen. Viele ausländische Unternehmen mit begrenzten Budgets wenden sich zunehmend an kostengünstige Modelle wie DeepSeek.
Nehmen wir als Beispiel die Taxivermittlungssoftware Uber, heißt es in früheren Berichten. Nach der Änderung des Preismodells für große Modelle war das KI-Budget des Unternehmens für das gesamte Jahr in nur 4 Monaten schnell aufgebraucht, was dazu führte, dass das Unternehmen die Nutzung durch Führungskräfte einschränken musste. Es sei ein Glück gewesen, „das erste große Unternehmen zu sein, das aufgehört hat, Geld für KI zu verbrennen“.
Auch Führungskräfte von Microsoft, Coinbase und anderen Unternehmen betonen, dass für viele Unternehmensaufgaben nicht immer die teuersten und größten Modelle erforderlich sind. Diese Änderungen haben Unternehmen dazu veranlasst, mehr „Multi-Modell-Routing“ einzuführen, d. h. einfache Aufgaben billigen Modellen und komplexe Aufgaben High-End-Modellen zuzuweisen.
Daher zeigen OpenRouter-Daten, dass Open-Source-Modelle etwa 65 % des Token-Verarbeitungsvolumens auf seiner Plattform ausmachen. Unter anderem hat die Nutzung von Low-Cost-Modellen in China, vertreten durch DeepSeek, deutlich zugenommen, was intuitiv zeigt, dass ausländische Benutzer in die Ära des „Kostenbewusstseins“ eingetreten sind.