Google hat heute Gemini 3.1 Flash-Lite offiziell vorgestellt und behauptet, es sei das schnellste und kostengünstigste Modell der Gemini 3-Serie. Es hieß außerdem, dass 3.1 Flash-Lite für umfangreiche Workloads mit hohem Durchsatz von Entwicklern konzipiert sei und in seiner Preisklasse und Modellebene eine äußerst hohe Qualität zeige.
Ab heute wird 3.1 Flash-Lite als Vorschau für Entwickler über die Gemini-Schnittstelle in Google AI Studio und für Unternehmensanwender über Vertex AI verfügbar sein.
3.1 Flash-Lite kostet 0,25 US-Dollar pro Million Input-Tokens (Input-Tokens) und 1,50 US-Dollar pro Million Output-Tokens (Output-Tokens). Laut dem Benchmark-Test von Artificial Analysis schneidet 3.1 Flash-Lite besser ab als 2.5 Flash bei gleicher oder höherer Qualität. Seine Antwortgeschwindigkeit beim ersten Wort (Time to First Answer Token) hat sich um das 2,5-fache erhöht, und auch die Ausgabegeschwindigkeit hat sich um 45 % erhöht. Laut Google ist diese Funktion mit geringer Latenz ein Muss für hochfrequente Arbeitsabläufe und damit ein ideales Modell für Entwickler, um reaktionsfähige Echtzeit-Erlebnisse zu erstellen.
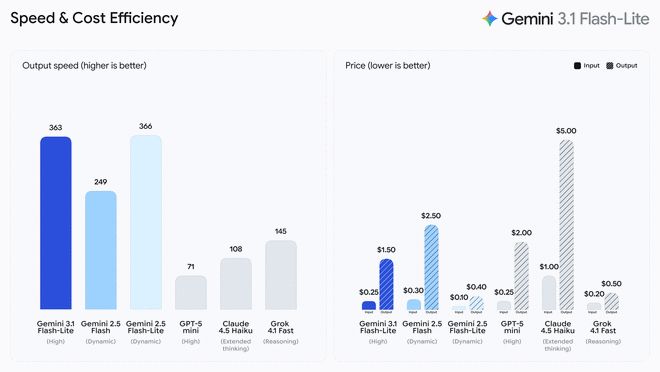
3.1 Flash-Lite erzielte 1432 Punkte auf der Arena.ai-Bestenliste. In verschiedenen Benchmark-Tests zum logischen Denken und zum multimodalen Verständnis übertrifft seine Leistung andere Modelle auf demselben Niveau. Beispielsweise erreichte es beim GPQA Diamond-Test eine Punktzahl von 86,9 % und beim MMMU Pro-Test eine Punktzahl von 76,8 %. Diese Leistung übertrifft sogar frühere Generationen größerer Modelle, wie z. B. den 2,5 Flash.
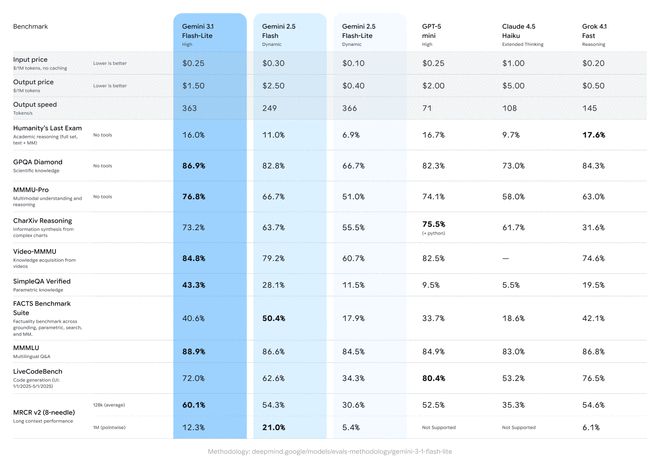
Zusätzlich zur nativen Leistung verfügt Gemini 3.1 Flash-Lite standardmäßig auch über die „Thinking Level“-Funktionalität in AI Studio und Vertex AI. Dies gibt Entwicklern die Flexibilität, zu steuern, wie tief ihre Modelle für bestimmte Aufgaben „denken“, was für die Bewältigung hochfrequenter Arbeitslasten von entscheidender Bedeutung ist. 3.1 Flash-Lite ist in der Lage, umfangreiche Aufgaben wie kostensensible, umfangreiche Übersetzungen und Inhaltsmoderation zu bewältigen. Gleichzeitig ist es auch in der Lage, komplexe Aufgaben zu bewältigen, die tiefgreifende Überlegungen erfordern, wie etwa das Generieren von Benutzeroberflächen und Dashboards, das Erstellen von Simulationsumgebungen und das Befolgen komplexer Anweisungen.
Google sagte, dass Early-Access-Entwickler von AI Studio und Vertex AI sowie Unternehmen wie Latitude, Cartwheel und Whering bereits 3.1 Flash-Lite verwenden, um komplexe Probleme in großem Maßstab zu lösen. Frühe Tester hoben die Effizienz und Inferenzfähigkeiten von 3.1 Flash-Lite hervor. Sie sagten, dass das Modell komplexe Eingaben mit der Genauigkeit großer Modelle verarbeiten, Anweisungen strikt befolgen und ein hohes Maß an Konsistenz aufrechterhalten könne.