AMD fördert eine Vision künstlicher Intelligenz, die nicht auf die Cloud angewiesen ist. Sein neu veröffentlichtes OpenClaw-Framework, gepaart mit zwei Sätzen von Hardware-Referenzkonfigurationen RyzenClaw und RadeonClaw, soll es Entwicklern und Early Adopters ermöglichen, große Sprachmodelle und Multi-Agent-Workflows auf lokalen PCs auszuführen. Dieser Schritt ist Teil des größeren „Agent Computer“-Plans von AMD, der davon ausgeht, dass die Zukunft der KI nicht auf entfernte Rechenzentren beschränkt sein sollte, sondern den Benutzern die Kontrolle über ihre eigene Daten- und Computerumgebung geben, lokale KI-Assistenten lange am Laufen halten, Netzwerkabhängigkeiten und Abonnementbelastungen reduzieren und Datenschutzbedenken ausräumen sollte.

Aus technischer Sicht läuft OpenClaw derzeit auf der Windows-Plattform über WSL2 (Windows-Subsystem für Linux 2), und LM Studio wird mit dem llama.cpp-Backend verwendet, um lokale Inferenzaufgaben durchzuführen. In dieser Umgebung können Benutzer Modelle einschließlich Qwen 3.5 35B A3B direkt auf dem Computer ausführen. Das System unterstützt außerdem ein eingebettetes Speicherframework namens Memory.md zum lokalen Speichern von Kontextinformationen, ohne auf Cloud-Synchronisierung angewiesen zu sein. AMD positioniert das offizielle Tutorial als relativ schlanken Konfigurationspfad, um Entwicklern den Aufbau einer vollständigen OpenClaw-Umgebung unter Windows und das Testen der KI-Agent-Architektur zu erleichtern, aber das Dokument gibt keine klare geschätzte Konfigurationszeit an.

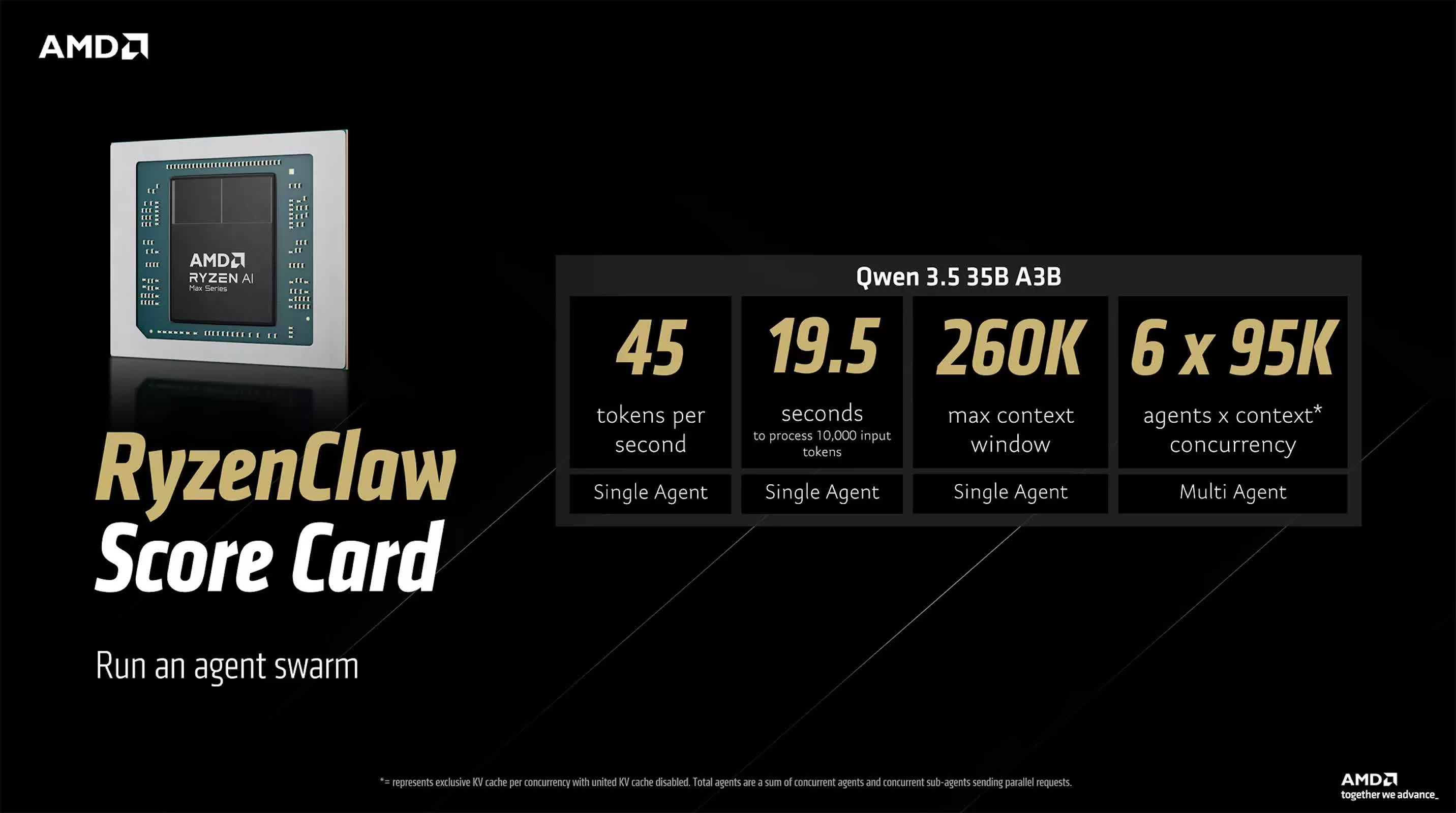
Die beiden von AMD vorgeschlagenen OpenClaw-Referenzen stellen unterschiedliche Wege hin zu „hochleistungsfähiger nativer KI“ dar. Die RyzenClaw-Lösung basiert auf dem Ryzen AI Max+-Prozessor und ist mit 128 GB einheitlichem Speicher ausgestattet, von dem AMD empfiehlt, etwa 96 GB als variablen Videospeicher zuzuweisen, um eine hohe Modellinferenzeffizienz zu gewährleisten. In dieser Konfiguration generiert Qwen 3.5 35B A3B etwa 45 Token pro Sekunde, benötigt etwa 19,5 Sekunden für die Verarbeitung einer Eingabe von 10.000 Token, unterstützt ein Kontextfenster von etwa 260.000 Token und kann in Multi-Agent-Workflows oder experimentellen „Agentencluster“-Umgebungen verwendet werden. Laut AMD kann die Plattform bis zu sechs lokale KI-Agenten gleichzeitig ausführen, was typisch für Systeme außerhalb von Rechenzentren ist.

Eine weitere RadeonClaw-Konfiguration verlagert den Schwerpunkt der Rechenleistung auf die unabhängige GPU – Radeon AI PRO R9700. Diese Grafikkarte der Workstation-Klasse bietet 32 GB dedizierten Grafikspeicher und erhöht so den Inferenzdurchsatz erheblich. Mit demselben Modell kann die Generierungsgeschwindigkeit auf etwa 120 Token pro Sekunde erhöht werden, wodurch sich die Zeit für die Verarbeitung einer Eingabe von 10.000 Token auf etwa 4,4 Sekunden verkürzt. Dieser Leistungsgewinn geht jedoch mit gewissen Kompromissen einher: Das maximale Kontextfenster wird auf etwa 190.000 Token reduziert und die Anzahl der gleichzeitigen Agenten wird auf 2 reduziert. Diese Unterschiede unterstreichen den Versuch von AMD, unterschiedliche Optimierungspfade bereitzustellen, die es Entwicklern ermöglichen, je nach Bedarf einen Kompromiss zwischen größerer Kontexttiefe und schnellerer Inferenz einzugehen.
Von der Positionierung her handelt es sich weder bei RyzenClaw noch bei RadeonClaw um eine Einstiegskonfiguration für Normalverbraucher. Nehmen wir als Beispiel RyzenClaw: Ein Desktop-Computer, der auf dem Ryzen AI Max+ 395-Chip basiert und mit 128 GB Speicher ausgestattet ist (wie der Framework Desktop-Plan), beginnt bei etwa 2.700 US-Dollar. Wenn Sie sich für RadeonClaw entscheiden, müssen Sie auch die Radeon AI PRO R9700-Grafikkarte kaufen, deren empfohlener Verkaufspreis allein etwa 1.299 US-Dollar beträgt. AMD gibt derzeit zu, dass die Hauptzielbenutzer von OpenClaw Ingenieure und Early Adopters sind, die mit lokalen KI-Agenten experimentieren, und nicht die Mainstream-PC-Benutzer.

Dennoch geht die Botschaft von OpenClaw über die spezifische Hardware selbst hinaus. AMD setzt auf einen Trend, bei dem Entwickler mehr Wert auf Autonomie und Datenschutz als auf Cloud-Erweiterungen legen, und hofft, durch lokale Agenten, die auf Consumer-Chips laufen, eine Brücke zwischen Personal Computing und verteilter KI zu schlagen. Wenn diese Idee vom Ökosystem anerkannt wird, wird AMD voraussichtlich eine einzigartige Position in der sich schnell entwickelnden KI-Landschaft einnehmen und es einigen High-End-Desktops und Workstations ermöglichen, schrittweise über KI-Verarbeitungsfunktionen in der Nähe von Rechenzentren zu verfügen und gleichzeitig ein Gefühl der Kontrolle und Flexibilität auf der Benutzerseite zu bewahren.