GPT-5.6 ist da, aber... um welches Modell handelt es sich? Dieses Mal verwendete OpenAI nicht die in der Vergangenheit bekannten Namen Pro, Mini und Instant. Stattdessen fielen gleich drei Namen auf:GPT-5.6 Sol, GPT-5.6 Terra, GPT-5.6 Luna.Sol ist die Sonne, Terra ist die Erde und Luna ist der Mond.
Klingt schick, nach einem neuen Modelluniversum. Aber es ist eigentlich die Produktschichtung, die wir kennen: das stärkste Flaggschiff-Modell, ein ausgewogenes Modell für den täglichen Gebrauch und ein leichtes Modell, das günstig, schnell und für große Anrufe geeignet ist.
Die offizielle Stellungnahme von OpenAI lautet:Die GPT-5.6-Serie wird in den kommenden Wochen vollständig verfügbar sein, befindet sich jedoch auf Wunsch der US-Regierung derzeit in einer begrenzten Vorschau für eine kleine Gruppe „vertrauenswürdiger Partner“ im Codex und der API.
Werfen wir zunächst einen Blick auf die öffentlich zugänglichen Informationen.

Die höchste Note hat den gleichen Preis wie GPT 5,5
OpenAI hat GPT-5.6 dieses Mal drei Stufen zugewiesen: Sol, Terra und Luna.
Laut offizieller Aussage ist Sol das Flaggschiffmodell, Terra ein ausgewogenes Modell für die tägliche Arbeit und Luna ein schnelles, günstiges und leichtes Modell.
Die dreistufigen Modelle wurden auf einmal veröffentlicht und entsprechen im Wesentlichen der häufigsten dreistufigen Struktur in großen Modellprodukten: Das stärkste Modell ist für die Obergrenze der Fähigkeiten verantwortlich, das mittlere Modell ist für die meisten täglichen Aufgaben verantwortlich und das leichte Modell ist für Geschwindigkeit, Kosten und hohe gleichzeitige Anrufe verantwortlich.
Das Niveau der drei lässt sich am Preis erkennen.
Laut dem von OpenAI bekannt gegebenen API-Preis,GPT-5.6 wird pro 1 Million Token berechnet: Sol kostet 5 US-Dollar für die Eingabe und 30 US-Dollar für die Ausgabe; Terra kostet 2,5 US-Dollar für den Input und 15 US-Dollar für den Output; und Luna kostet 1 US-Dollar für die Eingabe und 6 US-Dollar für die Ausgabe.
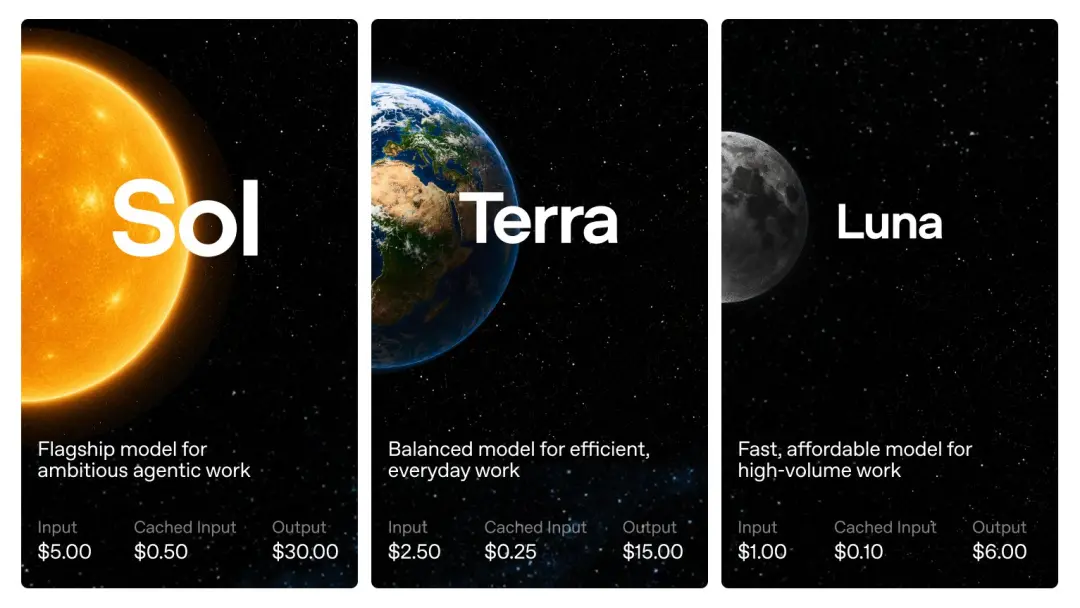
Ich glaube, Sie haben es vielleicht bemerkt: Obwohl es sich beim GPT-5.6 Sol um ein Flaggschiffmodell der neuen Generation handelt, entspricht der Preis der GPT-5.5-Standardversion und nicht der GPT-5.5 Pro.
Terra fiel direkt auf die Hälfte von GPT-5,5 und Luna erreichte nur ein Fünftel von GPT-5,5.
GPT-5.5 Pro ist derzeit immer noch das teuerste Modell von OpenAI. Der Preis beträgt 30 USD/Million Token für den Input und 180 USD/Million Token für den Output. Der Preis ist sechsmal so hoch wie der der GPT-5.5-Standardversion und der GPT-5.6-Sol. Ich weiß nicht, ob es in Zukunft ein weiteres GPT-5.6-Universum geben wird, das „besser für berufliche Aufgaben geeignet“ ist (nur ein Scherz).
Sol ist das High-End-Modell dieser GPT-5.6-Serie und es ist auch das Modell, das in der offiziellen Ankündigung am meisten vorgestellt wird.
OpenAI nennt GPT-5.6 Sol das derzeit stärkste Modell und konzentriert sich auf seine Fähigkeiten in den Bereichen Codierung, biologische Forschung und Netzwerksicherheit.
Um es einfach auszudrücken: Sol wird als „das beste Modell“ positioniert. Es handelt sich nicht um gewöhnliche Chat-Szenarien, sondern um Aufgaben, die komplexer und näher an der realen Arbeit sind.
Beispielsweise kann in einem Codeszenario ein Ziel weiter vorangetrieben werden: Zuerst das Problem verstehen, dann die Schritte aufschlüsseln, dann Tools aufrufen, Befehle ausführen, die Ergebnisse überprüfen und Korrekturen vornehmen, wenn Fehler auftreten, bis die Aufgabe abgeschlossen ist.
Um Sol bei der Bearbeitung schwierigerer Aufgaben zu unterstützen, hat OpenAI zwei neue Mechanismen in GPT-5.6 eingeführt.
Der erste heißtMaximaler Denkaufwand, was als „maximale Argumentationsstärke“ übersetzt werden kann.
Allgemeingültiges Verständnis bedeutet, dass Sol mehr Zeit hat, klar über das Problem nachzudenken, und dass es länger dauert, tiefgreifende Überlegungen anzustellen. Es eignet sich für komplexe Aufgaben, die nicht durch erste Reaktion gelöst werden können.
Der zweite heißtUltra-Modus,Es kann als „Supermodus“ verstanden werden.
Der Schwerpunkt dieses Modells liegt darauf, mehreren Subagenten die gemeinsame Teilnahme an komplexen Aufgaben zu ermöglichen. Man kann es so verstehen: Früher hat ein KI-Assistent alleine gearbeitet, heute führt ein „KI-Manager“ mehrere Assistenten dazu, Probleme getrennt zu bearbeiten und so den Fortschritt komplexer Arbeiten zu beschleunigen.
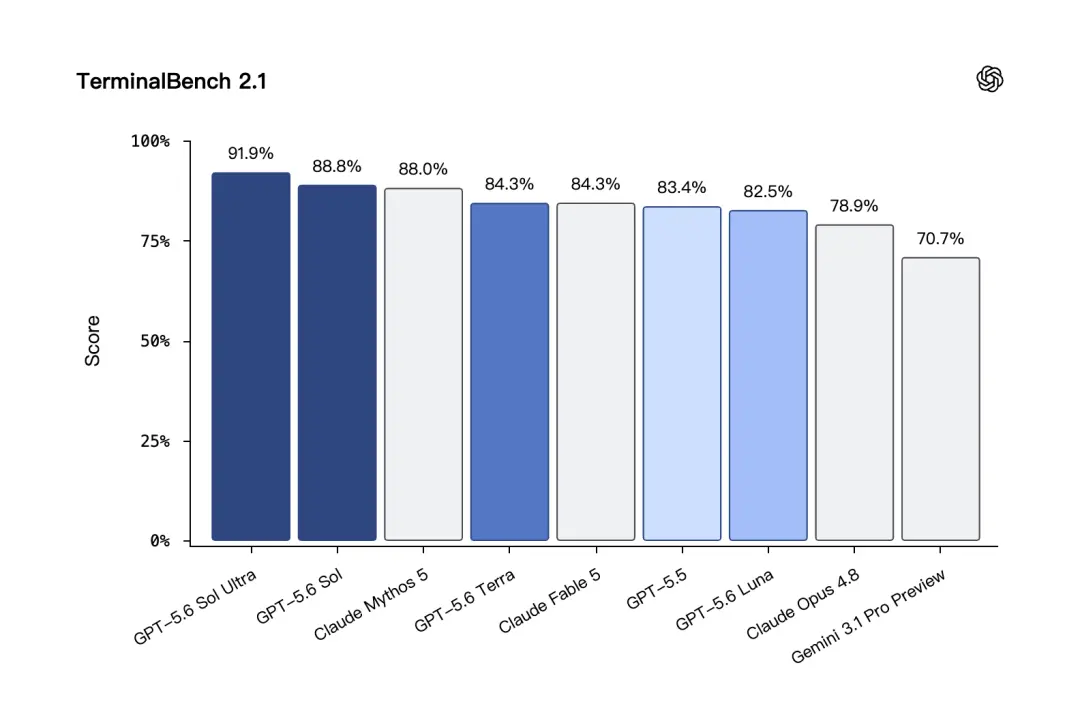
Terminal-Bench 2.1 ist ein Test, der näher am realen Entwicklungsprozess liegt. Es testet, ob das Modell das Problem Schritt für Schritt in der Kommandozeilenumgebung lösen kann. GPT-5.6 Sol erreichte in diesem Test eine hohe Punktzahl von 88,8 %, im Ultra-Modus war die Punktzahl sogar noch höher.
OpenAI erwähnte ausdrücklich, dass bei einer größeren Öffnung des Modells ein vollständigerer Satz an Evaluierungsergebnissen bekannt gegeben wird.
Terra ist die Mittelklasse.
Die Einführung von OpenAI in Terra ist nicht allzu lang, aber die Positionierung ist klar: Es ist ein ausgewogenes Modell für die tägliche Arbeit.
Das heißt, es wird nicht unbedingt der Stärkste verfolgt, sondern ein Gleichgewicht zwischen Wirkung, Geschwindigkeit und Kosten hergestellt. Beamte betonten, dass die Fähigkeiten von Terra nahe an GPT-5.5 liegen, der Preis jedoch halb so hoch sei.
In der Vision von OpenAI dürfte Terra das am häufigsten verwendete in der GPT-5.6-Serie sein. Gewöhnliche Büroaufgaben erfordern oft nicht die höchsten Fähigkeiten wie Sol, aber sie müssen stabil, kostengünstig und einfach zu bedienen sein.
Im Terminal-Bench 2.1-TestGPT-5.6 Terra erreichte 84,3 %, was dem gleichen Wert wie Claude Fable 5 entspricht.
Luna ist die günstigste Preisklasse.
Auch die Positionierung von Luna durch OpenAI ist sehr einfach: schnell, günstig und für groß angelegte, hochfrequente und kostensensible Aufgaben geeignet.
Zum Beispiel Stapelzusammenfassung, Textklassifizierung, Informationsextraktion, einfache Frage und Antwort usw. Diese Aufgaben selbst sind nicht unbedingt komplex, aber das Anrufvolumen kann sehr groß sein. Die Rolle von Luna besteht darin, diese leichten Aufgaben zu geringeren Kosten auszuführen.
Unter diesen drei Modellen ist Sol für die höchsten Fähigkeiten verantwortlich, Terra für die tägliche Arbeit und Luna für Geschwindigkeit und Kosten. Es klingt ausgefallen, aber OpenAI verpackt lediglich die bereits ausgereiften Schichten der großen Modellindustrie neu.
Aber ich denke, der Name ist nicht wichtig, solange er billig und einfach zu verwenden ist.

Preis-Leistungs-Verhältnis
Wenn man sich nur die offizielle Ankündigung ansieht, sind die von GPT-5.6 Sol dieses Mal veröffentlichten Benchmarks nicht viele. OpenAI selbst sagte, dass es jetzt nur noch darum geht, die Außenwelt im Voraus über die Modellleistung zu informieren, sodass zunächst eine Reihe von Bewertungsergebnissen geteilt werden.
Die veröffentlichten Benchmarks haben jedoch eine klare Richtung und konzentrieren sich auf drei Bereiche: Code, Biologie und Netzwerksicherheit.
Die oben erwähnte Terminal-Bench 2.1 gehört zur Coderichtung. Es testet, ob das Modell den realen Entwicklungsprozess in der Befehlszeilenumgebung abschließen kann, einschließlich Planung, wiederholten Änderungen, Aufrufen von Tools und Überprüfen der Ergebnisse.
Zusätzlich zum Code hat OpenAI auch einen biologischen Benchmark hervorgehoben: GeneBench v1.
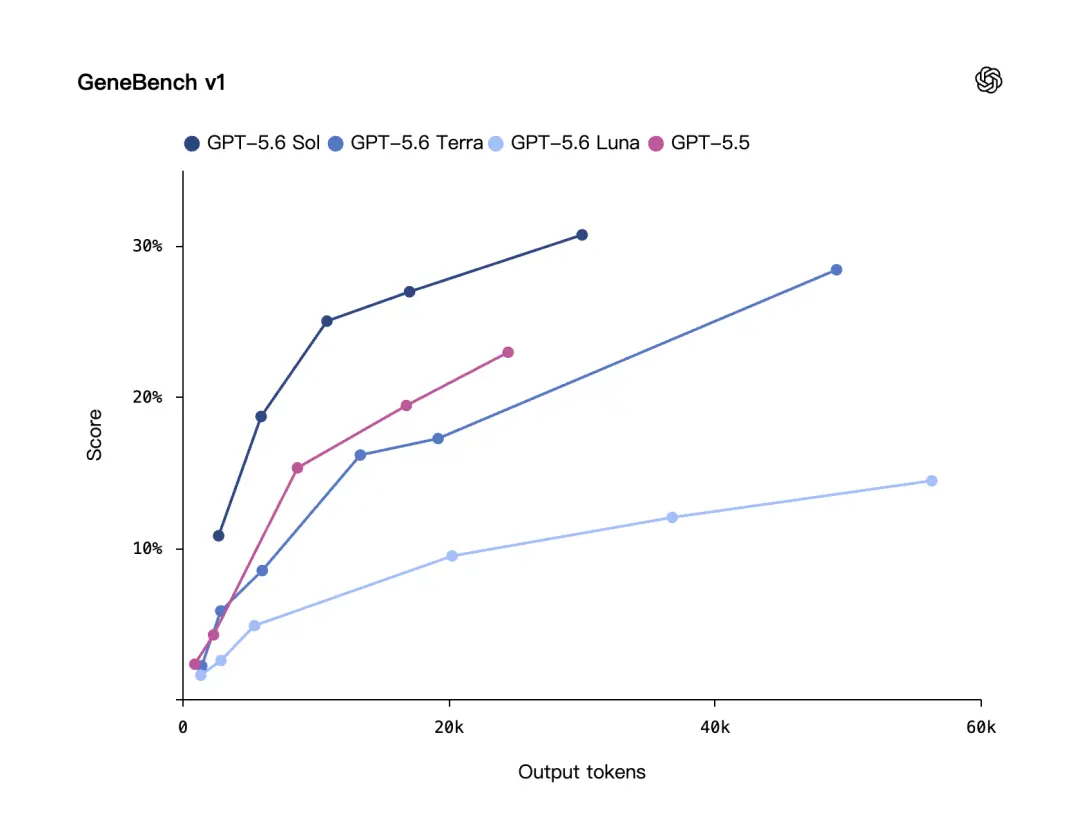
GeneBench v1 bewertet Langzeitgenomik- und quantitative biologische Analyseaufgaben und konzentriert sich dabei darauf, ob das Modell Analyseprobleme bewältigen kann, die näher am realen wissenschaftlichen Forschungsprozess liegen.
Laut OpenAI schneidet GPT-5.6 Sol auf GeneBench v1 besser ab als GPT-5.5Verwenden Sie weniger Token.
Die dritte Schlüsselrichtung ist die Netzwerksicherheit. OpenAI behauptet, dass GPT-5.6 Sol sein derzeit stärkstes Netzwerksicherheitsmodell ist, insbesondere für langfristige Sicherheitsaufgaben (einschließlich Schwachstellenforschung und Aufgaben im Zusammenhang mit der Ausnutzung von Schwachstellen).
Hier gibt es einen Benchmark namens ExploitBench – es handelt sich nicht um eine allgemeine Sicherheitsfrage und -antwort, sondern um eine Bewertung, die näher an Szenarien zur Ausnutzung von Sicherheitslücken liegt.
OpenAI sagte das auf ExploitBench:Die Leistung von GPT-5.6 Sol ist vergleichbar mit Mythos Preview, nutzt jedoch nur etwa ein Drittel der Ausgabetokens.
Allerdings gibt es immer noch eine gewisse Lücke im offiziellen Bild.
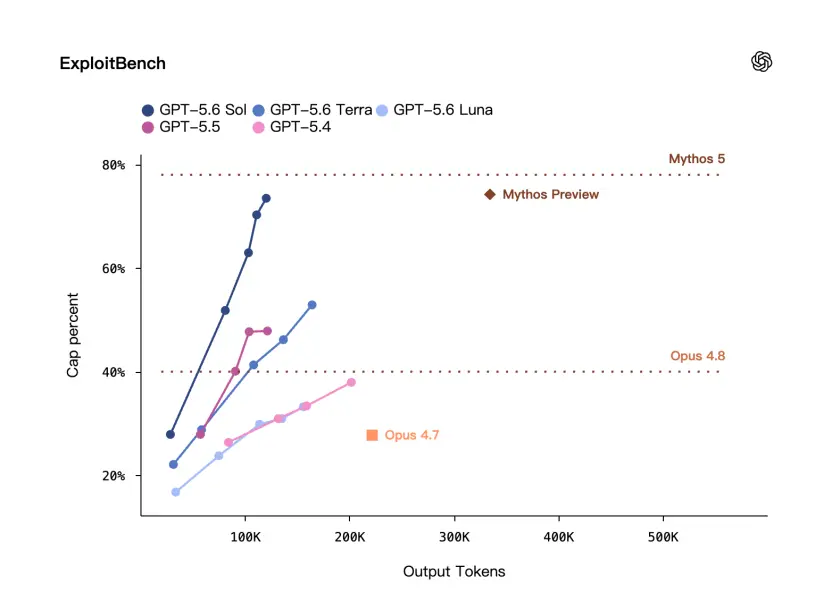
Es ist ersichtlich, dass OpenAI dieses Mal wiederholt betont hat:Sie sind zwar äußerst leistungsfähig, aber auch äußerst effizient.
Weniger Ausgabetokens bedeuten, dass das Modell möglicherweise prägnanter ist und bei der Erledigung ähnlicher Aufgaben weniger Umwege erfordert, und es kann auch bedeuten, dass die tatsächlichen Anrufkosten besser kontrollierbar sind.
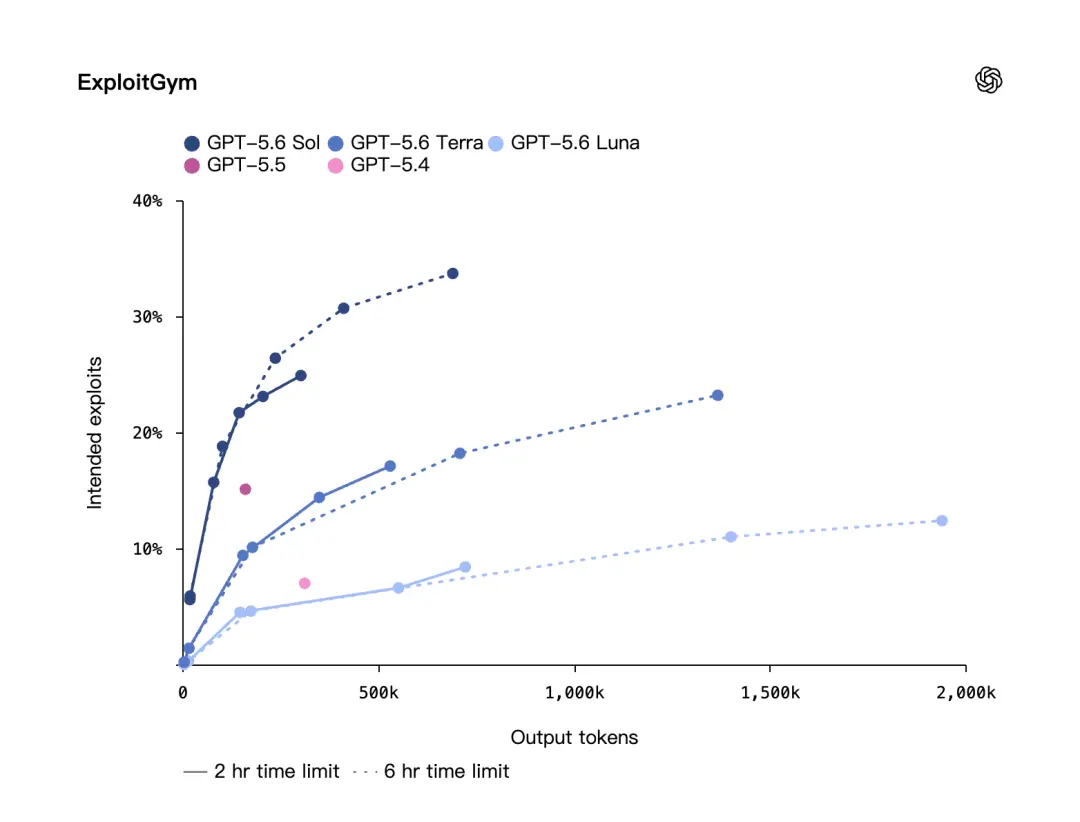
OpenAI erwähnte auch einen weiteren Benchmark für Cybersicherheit: ExploitGym.
Dieser Benchmark wurde von Forschern der UC Berkeley in Zusammenarbeit mit OpenAI und anderen hochmodernen Labors erstellt. OpenAI sagte, dass bei ExploitGym die GPT-5.6-Modelle Sol, Terra und Luna alle eine deutliche Verbesserung der Netzwerksicherheitsfähigkeiten zeigen und mit zunehmender Inferenzintensität die Leistung stärker wird.
Dies bedeutet, dass es bei der Verbesserung von GPT-5.6 nicht nur um den stärkeren Modellkörper geht, sondern auch um die Argumentationsmethode. Geben Sie dem Modell mehr Zeit zum Nachdenken und lassen Sie es eine längere Argumentationskette durchlaufen, und die Ergebnisse werden besser sein.

Informationen zur eingeschränkten Vorschau
Wenn Sol, Terra und Luna die oberflächlichen Änderungen von GPT-5.6 sind, dann verdient mehr Aufmerksamkeit, dass OpenAI dieses Mal nicht vollständig geöffnet wurde.
Der offiziellen Ankündigung zufolge wird GPT-5.6 derzeit nur für eine begrenzte Vorschau im Codex und in der API einer kleinen Gruppe „vertrauenswürdiger Partner“ zur Verfügung stehen.
Darüber hinaus wurde diese begrenzte Vorschau „auf Wunsch der US-Regierung“ durchgeführt und die Liste der an der Vorschau teilnehmenden Partner wurde der US-Regierung mitgeteilt.
In jüngster Zeit hat die US-Regierung ihre Beteiligung an hochmodernen KI-Modellen erheblich verstärkt, insbesondere an solchen mit stärkerem Code, besserer Netzwerksicherheit und stärkeren Agentenfähigkeiten.
Im Juni dieses Jahres erließ die US-Regierung eine neue Durchführungsverordnung zur KI-Cybersicherheit und schlug die Schaffung eines freiwilligen Rahmens vor, der es hochmodernen Modellentwicklern ermöglicht, das Modell zu kontaktieren und zu bewerten, bevor es in größerem Umfang veröffentlicht wird.
Die Rechtsgemeinschaft interpretiert diese Verwaltungsanordnung so, dass es sich weder um eine Zwangslizenz im Namen noch um ein formelles Genehmigungssystem handelt, sondern dass sie einen institutionellen Rahmen für die Beteiligung der Regierung an der Modellbewertung vor der Freigabe geschaffen hat.
Das Veröffentlichungsmodell von GPT-5.6 Sol mit der „ersten Vorschau in kleinem Maßstab und der Weitergabe der Liste an die Regierung“ kann als erste klare Spur staatlicher Eingriffe in den Veröffentlichungsprozess des Spitzenmodells angesehen werden.
OpenAI selbst erklärte in der Ankündigung auch, dass der Grund für diesen Ansatz darin bestehe, mit der Regierung einen wiederholbaren Prozess zur Unterstützung zukünftiger Modellveröffentlichungen auszuloten.
Der Hauptgrund für staatliche Eingriffe ist die Netzwerksicherheit.
In der offiziellen Ankündigung nimmt die Netzwerksicherheit viel Platz ein: OpenAI betont, dass GPT-5.6 Sol derzeit sein stärkstes Netzwerksicherheitsmodell ist und bei langfristigen Aufgaben wie Schwachstellenforschung, Schwachstellenanalyse und Sicherheitsverteidigung stärker helfen kann; Andererseits wird viel Raum darauf verwendet, zu erklären, dass es seine eigene Cyber-kritische Schwelle nicht überschritten hat.
Im Vorbereitungsframework von OpenAI werden Hochrisikofunktionen in verschiedene Ebenen unterteilt. Das Erreichen von „Hoch“ bedeutet, dass das Modell bestehende schwerwiegende Risiken verstärken kann; Kritisch zu erreichen bedeutet, dass das Modell möglicherweise neue und beispiellose schwerwiegende Risiken mit sich bringt.
OpenAI hat wiederholt betont, dass GPT-5.6 Sol nicht Cyber Critical erreicht. Tatsächlich sagt es der Regierung, den Kunden und der Öffentlichkeit: Dieses Modell ist sehr stark, insbesondere bei Netzwerksicherheitsaufgaben, aber es ist nicht stark genug, um die gefährlichsten Netzwerkangriffsketten selbstständig abzuschließen.
Netzwerksicherheitsfunktionen sind wie ein zweischneidiges Schwert. Je stärker sie sind, desto mehr können sie Verteidigern helfen, Schwachstellen zu finden, Patches zu schreiben und Sicherheitstests durchzuführen. Aber gerade weil sie so stark sind, wird die Regierung auch über ihren Missbrauch besorgt sein.
Obwohl OpenAI zugab, dass diese Veröffentlichung eine Prüfung des Prozesses mit der Regierung erfordert, machte es in der offiziellen Ankündigung auch deutlich, dass OpenAI nicht der Meinung ist, dass dieser staatliche Zugriffsprozess zum langfristigen Standardmechanismus werden sollte.
Der Grund: Wenn die leistungsstärksten Tools verzögert werden, wird es für Benutzer, Entwickler, Unternehmen, Netzwerkverteidiger und Partner auf der ganzen Welt zu Verzögerungen beim Erhalt der besten Tools kommen.
In gewisser Weise treten hochmoderne Modelle in eine neue Release-Phase ein.
Wenn sich die Fähigkeiten großer Modelle auf Bereiche wie Code, Biologie, Netzwerksicherheit und Agentenausführung konzentrieren, wird sie als eine Technologie betrachtet, die das Potenzial hat, Auswirkungen auf die Sicherheit in der realen Welt zu haben.
Wenn man die Technologie so betrachtet, ist es schwierig, dass die Veröffentlichungsrechte vollständig in den Händen des Unternehmens selbst bleiben.